import sqlite3
conn = sqlite3.connect('D:/data/sqlite3/INSTRUCTOR.db')Cursor Class
SQlite3 & Python
This first section will cover how to create and manipulate a db with Python & SQL
SQLite3 is an in-process Python library that implements a self-contained, serverless, zero-configuration, transactional SQL database engine. It is a popular choice as an embedded database for local/client storage in application software.
A complete example can be found at Scrape Table - Create DB and Import CSV - Create DB in the Howto section
Connect & Create db
sqlite3.connect
- After you install it in Python
- Import it then
- To connect to SQLite3 use the
connectfunction and pass it the db as an argument - This makes the variable
connan object of the SQL code engine. You can then use this to run the required queries on the database.
Cursor class is an instance using which you can invoke methods that execute SQLite statements, fetch data from the result sets of the queries. You can create Cursor object using the cursor() method of the Connection object/class.
cursor_obj = conn.cursor()Create Table
We’ll create a table with the following definition:
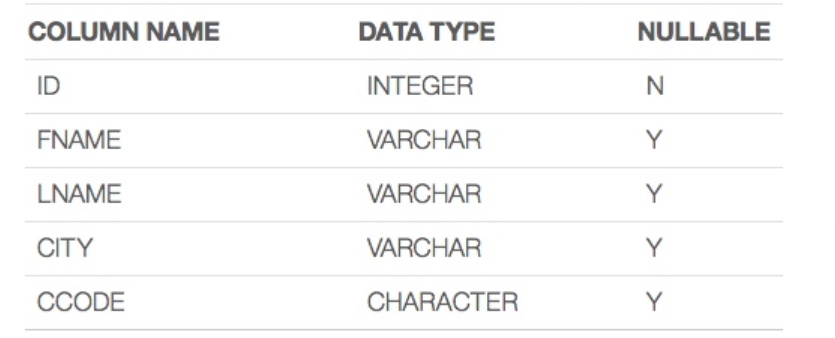
Check if Table exists
- If the table doesn’t exist you’ll most likely get an Exception Error that INSTRUCTOR table is undefined
# Drop the table if already exists.
cursor_obj.execute("DROP TABLE IF EXISTS Instructor")<sqlite3.Cursor at 0x240f52d5cc0>Define & Create Table
# Define table
table = """ create table IF NOT EXISTS Instructor(ID INTEGER PRIMARY KEY NOT NULL, FNAME VARCHAR(20), LNAME VARCHAR(20), CITY VARCHAR(20), CCODE CHAR(2));"""
# Create table
cursor_obj.execute(table)
print("Table is Ready")Table is Ready- You can also check and see if the db was created at the specified location
Populate Table
Insert data
# Insert one row
cursor_obj.execute('''insert into INSTRUCTOR values (1, 'Rav', 'Ahuja', 'TORONTO', 'CA')''')
# Insert multiple rows
cursor_obj.execute('''insert into INSTRUCTOR values (2, 'Raul', 'Chong', 'Markham', 'CA'),
(3, 'Hima', 'Vasudevan', 'Chicago', 'US')''')<sqlite3.Cursor at 0x240f52d5cc0>Query Table
Fetchall() Rows
- Let’s review the data we inserted
q1 = '''SELECT *
FROM Instructor'''
cursor_obj.execute(q1)
print("All the data")
output_all = cursor_obj.fetchall()
for row_all in output_all:
print(row_all)All the data
(1, 'Rav', 'Ahuja', 'TORONTO', 'CA')
(2, 'Raul', 'Chong', 'Markham', 'CA')
(3, 'Hima', 'Vasudevan', 'Chicago', 'US')Fetchmany() Rows
- We can edit the query to filter the rows, let’s say we want the top 2 rows
- We can use
fetchmany(2)with python to do the same
## Fetch few rows from the table
statement = ''' SELECT *
FROM Instructor'''
cursor_obj.execute(statement)
print("All the data")
# If you want to fetch few rows from the table we use fetchmany(numberofrows) and mention the number how many rows you want to fetch
output_many = cursor_obj.fetchmany(2)
for row_many in output_many:
print(row_many)All the data
(1, 'Rav', 'Ahuja', 'TORONTO', 'CA')
(2, 'Raul', 'Chong', 'Markham', 'CA')# Or we can edit the SQL query q1 by adding LIMIT and repeat the first chunk of code
q2 = '''SELECT *
FROM Instructor
LIMIT 2'''
cursor_obj.execute(q2)
print("All the data")
output_all = cursor_obj.fetchall()
for row_all in output_all:
print(row_all)All the data
(1, 'Rav', 'Ahuja', 'TORONTO', 'CA')
(2, 'Raul', 'Chong', 'Markham', 'CA')Update() Values
- Let’s change Rav’s city to MOOSETOWN
query_update='''
UPDATE Instructor
SET CITY='MOOSETOWN'
WHERE FNAME="Rav"
'''
cursor_obj.execute(query_update)
# Let's run the previous query to view entire table
q1 = '''SELECT *
FROM Instructor'''
cursor_obj.execute(q1)
conn.commit()
print("All the data")
output_all = cursor_obj.fetchall()
for row_all in output_all:
print(row_all)All the data
(1, 'Rav', 'Ahuja', 'MOOSETOWN', 'CA')
(2, 'Raul', 'Chong', 'Markham', 'CA')
(3, 'Hima', 'Vasudevan', 'Chicago', 'US')Create Another Table
# Check if table exists and drop it
cursor_obj.execute("DROP TABLE IF EXISTS Scores")
# Define table
table2 = """ CREATE TABLE IF NOT EXISTS Scores(
country VARCHAR(50),
first_name VARCHAR(50),
last_name VARCHAR(50),
test_score INT)"""
# Excecute the creation of the table
cursor_obj.execute(table2)
print("Table is Ready")
# Insert Data into Scores
q_insert ="""INSERT INTO Scores (country, first_name, last_name, test_score)
VALUES
('United States', 'Marshall', 'Bernadot', 54),
('Ghana', 'Celinda', 'Malkin', 51),
('Ukraine', 'Guillermo', 'Furze', 53),
('Greece', 'Aharon', 'Tunnow', 48),
('Russia', 'Bail', 'Goodwin', 46),
('Poland', 'Cole', 'Winteringham', 49),
('Sweden', 'Emlyn', 'Erricker', 55),
('Russia', 'Cathee', 'Sivewright', 49),
('China', 'Barny', 'Ingerson', 57),
('Uganda', 'Sharla', 'Papaccio', 55),
('China', 'Stella', 'Youens', 51),
('Poland', 'Julio', 'Buesden', 48),
('United States', 'Tiffie', 'Cosely', 58),
('Poland', 'Auroora', 'Stiffell', 45),
('China', 'Clarita', 'Huet', 52),
('Poland', 'Shannon', 'Goulden', 45),
('Philippines', 'Emylee', 'Privost', 50),
('France', 'Madelina', 'Burk', 49),
('China', 'Saunderson', 'Root', 58),
('Indonesia', 'Bo', 'Waring', 55),
('China', 'Hollis', 'Domotor', 45),
('Russia', 'Robbie', 'Collip', 46),
('Philippines', 'Davon', 'Donisi', 46),
('China', 'Cristabel', 'Radeliffe', 48),
('China', 'Wallis', 'Bartleet', 58),
('Moldova', 'Arleen', 'Stailey', 38),
('Ireland', 'Mendel', 'Grumble', 58),
('China', 'Sallyann', 'Exley', 51),
('Mexico', 'Kain', 'Swaite', 46),
('Indonesia', 'Alonso', 'Bulteel', 45),
('Armenia', 'Anatol', 'Tankus', 51),
('Indonesia', 'Coralyn', 'Dawkins', 48),
('China', 'Deanne', 'Edwinson', 45),
('China', 'Georgiana', 'Epple', 51),
('Portugal', 'Bartlet', 'Breese', 56),
('Azerbaijan', 'Idalina', 'Lukash', 50),
('France', 'Livvie', 'Flory', 54),
('Malaysia', 'Nonie', 'Borit', 48),
('Indonesia', 'Clio', 'Mugg', 47),
('Brazil', 'Westley', 'Measor', 48),
('Philippines', 'Katrinka', 'Sibbert', 51),
('Poland', 'Valentia', 'Mounch', 50),
('Norway', 'Sheilah', 'Hedditch', 53),
('Papua New Guinea', 'Itch', 'Jubb', 50),
('Latvia', 'Stesha', 'Garnson', 53),
('Canada', 'Cristionna', 'Wadmore', 46),
('China', 'Lianna', 'Gatward', 43),
('Guatemala', 'Tanney', 'Vials', 48),
('France', 'Alma', 'Zavittieri', 44),
('China', 'Alvira', 'Tamas', 50),
('United States', 'Shanon', 'Peres', 45),
('Sweden', 'Maisey', 'Lynas', 53),
('Indonesia', 'Kip', 'Hothersall', 46),
('China', 'Cash', 'Landis', 48),
('Panama', 'Kennith', 'Digance', 45),
('China', 'Ulberto', 'Riggeard', 48),
('Switzerland', 'Judy', 'Gilligan', 49),
('Philippines', 'Tod', 'Trevaskus', 52),
('Brazil', 'Herold', 'Heggs', 44),
('Latvia', 'Verney', 'Note', 50),
('Poland', 'Temp', 'Ribey', 50),
('China', 'Conroy', 'Egdal', 48),
('Japan', 'Gabie', 'Alessandone', 47),
('Ukraine', 'Devlen', 'Chaperlin', 54),
('France', 'Babbette', 'Turner', 51),
('Czech Republic', 'Virgil', 'Scotney', 52),
('Tajikistan', 'Zorina', 'Bedow', 49),
('China', 'Aidan', 'Rudeyeard', 50),
('Ireland', 'Saunder', 'MacLice', 48),
('France', 'Waly', 'Brunstan', 53),
('China', 'Gisele', 'Enns', 52),
('Peru', 'Mina', 'Winchester', 48),
('Japan', 'Torie', 'MacShirrie', 50),
('Russia', 'Benjamen', 'Kenford', 51),
('China', 'Etan', 'Burn', 53),
('Russia', 'Merralee', 'Chaperlin', 38),
('Indonesia', 'Lanny', 'Malam', 49),
('Canada', 'Wilhelm', 'Deeprose', 54),
('Czech Republic', 'Lari', 'Hillhouse', 48),
('China', 'Ossie', 'Woodley', 52),
('Macedonia', 'April', 'Tyer', 50),
('Vietnam', 'Madelon', 'Dansey', 53),
('Ukraine', 'Korella', 'McNamee', 52),
('Jamaica', 'Linnea', 'Cannam', 43),
('China', 'Mart', 'Coling', 52),
('Indonesia', 'Marna', 'Causbey', 47),
('China', 'Berni', 'Daintier', 55),
('Poland', 'Cynthia', 'Hassell', 49),
('Canada', 'Carma', 'Schule', 49),
('Indonesia', 'Malia', 'Blight', 48),
('China', 'Paulo', 'Seivertsen', 47),
('Niger', 'Kaylee', 'Hearley', 54),
('Japan', 'Maure', 'Jandak', 46),
('Argentina', 'Foss', 'Feavers', 45),
('Venezuela', 'Ron', 'Leggitt', 60),
('Russia', 'Flint', 'Gokes', 40),
('China', 'Linet', 'Conelly', 52),
('Philippines', 'Nikolas', 'Birtwell', 57),
('Australia', 'Eduard', 'Leipelt', 53)
"""
# Execute insert data
cursor_obj.execute(q_insert)
conn.commit()Table is Ready# Let's run the previous query to view entire table
q3 = '''SELECT *
FROM Scores
LIMIT 10'''
cursor_obj.execute(q3)
print("First 10 rows")
output_all = cursor_obj.fetchall()
for row_all in output_all:
print(row_all)First 10 rows
('United States', 'Marshall', 'Bernadot', 54)
('Ghana', 'Celinda', 'Malkin', 51)
('Ukraine', 'Guillermo', 'Furze', 53)
('Greece', 'Aharon', 'Tunnow', 48)
('Russia', 'Bail', 'Goodwin', 46)
('Poland', 'Cole', 'Winteringham', 49)
('Sweden', 'Emlyn', 'Erricker', 55)
('Russia', 'Cathee', 'Sivewright', 49)
('China', 'Barny', 'Ingerson', 57)
('Uganda', 'Sharla', 'Papaccio', 55)Import to Pandas
Read_sql
- To query a database table using SQLite3 and Pandas use the function
read_sql()to query a database table - The function returns a df with the output of the query
- Now you can use Python to manipulate the df as you normally would
- Determine your SQL query which will be used as argument
- Your connection var will be used as the other argument
import pandas as pd
query_statement='''SELECT *
FROM Instructor'''
df = pd.read_sql(query_statement, conn)
df| ID | FNAME | LNAME | CITY | CCODE | |
|---|---|---|---|---|---|
| 0 | 1 | Rav | Ahuja | MOOSETOWN | CA |
| 1 | 2 | Raul | Chong | Markham | CA |
| 2 | 3 | Hima | Vasudevan | Chicago | US |
Here are some example queries that we are familiar with from SQL
| Query statement | Purpose |
|---|---|
| SELECT * FROM table_name | Retrieve all entries of the table. |
| SELECT COUNT(*) FROM table_name | Retrieve total number of entries in the table. |
| SELECT Column_name FROM table_name | Retrieve all entries of a specific column in the table. |
| SELECT * FROM table_name WHERE <condition> | Retrieve all entries of the table that meet the specified condition. |
Explore df
# To view second row FNAME of df
df.LNAME[1]'Chong'# Review number of (rows, columns)
df.shape(3, 5)Export From Pandas
To_sql
- You can directly load a Pandas dataframe to a SQLite3 database object using the following syntax.
- Use the
to_sql()function to convert thepandasdataframe to an SQL table. - The
table_nameandsql_connectionarguments specify the name of the required table and the database to which you should load the dataframe. - The
if_existsparameter can take any one of three possible values:'fail': This denies the creation of a table if one with the same name exists in the database already.'replace': This overwrites the existing table with the same name.'append': This adds information to the existing table with the same name.
- Keep the
indexparameter set toTrueonly if the index of the data being sent holds some informational value. Otherwise, keep it asFalse.
df.to_sql(table_name, sql_connection, if_exists = 'replace', index = False)Close Connection
Always close the connection when done
conn.close()Python & SQL Summary
SQLite
| Topic | Syntax | Description |
|---|---|---|
| connect() | sqlite3.connect() |
Create a new database and open a database connection to allow sqlite3 to work with it. Call sqlite3.connect() to create a connection to the database INSTRUCTOR.db in the current working directory, implicitly creating it if it does not exist. |
| cursor() | con.cursor() |
To execute SQL statements and fetch results from SQL queries, use a database cursor. Call con.cursor() to create the Cursor. |
| execute() | cursor_obj.execute() |
The execute method in Python’s SQLite library allows to perform SQL commands, including retrieving data from a table using a query like “Select * from table_name.” When you execute this command, the result is obtained as a collection of table data stored in an object, typically in the form of a list of lists. |
| fetchall() | cursor_obj.fetchall() |
The fetchall() method in Python retrieves all the rows from the result set of a query and presents them as a list of tuples. |
| fetchmany() | cursor_obj.fetchmany() |
The fetchmany() method retrieves the subsequent group of rows from the result set of a query rather than just a single row. To fetch a few rows from the table, use fetchmany(numberofrows) and mention how many rows you want to fetch. |
| read_sql_query() | read_sql_query() |
read_sql_query() is a function provided by the Pandas library in Python, and it is not specific to MySQL. It is a generic function used for executing SQL queries on various database systems, including MySQL, and retrieving the results as a Pandas DataFrame. |
| shape | dataframe.shape |
It provides a tuple indicating the shape of a DataFrame or Series, represented as (number of rows, number of columns). |
| close() | con.close() |
con.close() is a method used to close the connection to a MySQL database. When called, it terminates the connection, releasing any associated resources and ensuring the connection is no longer active. This is important for managing database connections efficiently and preventing resource leaks in your MySQL database interactions. |
| CREATE TABLE | CREATE TABLE table_name ( column1 datatype constraints, column2 datatype constraints, ... ); |
The CREATE TABLE statement is used to define and create a new table within a database. It specifies the table’s name, the structure of its columns (including data types and constraints), and any additional properties such as indexes. This statement essentially sets up the blueprint for organizing and storing data in a structured format within the database. |
| barplot() | seaborn.barplot(x="x-axis_variable", y="y-axis_variable", data=data) |
seaborn.barplot() is a function in the Seaborn Python data visualization library used to create a bar plot, also known as a bar chart. It is particularly used to display the relationship between a categorical variable and a numeric variable by showing the average value for each category. |
| read_csv() | df = pd.read_csv('file_path.csv') |
read_csv() is a function in Python’s Pandas library used for reading data from a Comma-Separated Values (CSV) file and loading it into a Pandas DataFrame. It’s a common method for working with tabular data stored in CSV format |
| to_sql() | df.to_sql('table_name', index=False) |
df.to_sql() is a method in Pandas, a Python data manipulation library used to write the contents of a DataFrame to a SQL database. It allows to take data from a DataFrame and store it structurally within a SQL database table. |
| read_sql() | df = pd.read_sql(sql_query, conn) |
read_sql() is a function provided by the Pandas library in Python for executing SQL queries and retrieving the results into a DataFrame from an SQL database. It’s a convenient way to integrate SQL database interactions into your data analysis workflows. |
Db2
| Topic | Syntax | Description | Example |
|---|---|---|---|
| connect() | conn = ibm_db.connect('DATABASE=dbname; HOST=hostname;PORT=port;UID=username; PWD=password;', '', '') |
ibm_db.connect() is a Python function provided by the ibm_db library, which is used for establishing a connection to an IBM Db2 or IBM Db2 Warehouse database. It’s commonly used in applications that need to interact with IBM Db2 databases from Python. |
|
| server_info() | ibm_db.server_info() |
ibm_db.server_info(conn) is a Python function provided by the ibm_db library, which is used to retrieve information about the IBM Db2 server to which you are connected. |
|
| close() | con.close() |
con.close() is a method used to close the connection to a db2 database. When called, it terminates the connection, releasing any associated resources and ensuring the connection is no longer active. This is important for managing database connections efficiently and preventing resource leaks in your db2 database interactions. |
|
| exec_immediate() | sql_statement = "SQL statement goes here"stmt = ibm_db.exec_immediate(conn, sql_statement) |
ibm_db.exec_immediate() is a Python function provided by the ibm_db library, which is used to execute an SQL statement immediately without the need to prepare or bind it. It’s commonly used for executing SQL statements that don’t require input parameters or don’t need to be prepared in advance. |
Jupyter
To communicate with SQL Databases from within a JupyterLab notebook, we can use the SQL “magic” provided by the ipython-sql extension. “Magic” is JupyterLab’s term for special commands that start with “%”. Below, we’ll use the load_ext magic to load the ipython-sql extension. In the lab environemnt provided in the course the ipython-sql extension is already installed and so is the ibm_db_sa driver.
import sqlite3
%load_ext sql
%sql sqlite://D:/data/sqlite3/INSTRUCTOR.dbSQL Cell
- Now you can run SQL queries in the cells
- %%sql on the first line of the cell indicates the entire cell should be treated as SQL
%%sql
CREATE TABLE INTERNATIONAL_STUDENT_TEST_SCORES (
country VARCHAR(50),
first_name VARCHAR(50),
last_name VARCHAR(50),
test_score INT
);
INSERT INTO INTERNATIONAL_STUDENT_TEST_SCORES (country, first_name, last_name, test_score)
VALUES
('United States', 'Marshall', 'Bernadot', 54),
('Ghana', 'Celinda', 'Malkin', 51),
('Ukraine', 'Guillermo', 'Furze', 53),
('Greece', 'Aharon', 'Tunnow', 48),
('Russia', 'Bail', 'Goodwin', 46),
('Poland', 'Cole', 'Winteringham', 49),SQL & Python Cell
- To mix SQL and Python
- If country is a python var
country = 'Canada'
%sql SELECT * FROM INTERNATIONAL_STUDENT_TEST_SCORES WHERE country = :countryAssign Results to Var
- We can assign the results of a query to a python var
test_score_distribution = %sql SELECT test_score as "Test_Score", count(*) as "Frequency" from INTERNATIONAL_STUDENT_TEST_SCORES GROUP BY test_score;
test_score_distributionConvert Results to df
dataf = test_score_distribution.DataFrame()