$ export PGPASSWORD=cccttt
$ createdb -h postgres -U postgres -p 5432 billingDWDownload Schema Script
Facts & Dimensional Modeling
Data can be lumped into two categories: Facts and dimensions;
Facts are usually quantities which can be measured, such as temperature, number of sales, or millimeters of rainfall. But facts can also be qualitative in nature.
On the other hand;
Dimensions are attributes which can be assigned to facts. Dimensions provide context to facts, which makes facts useful.
For example, a temperature such as “24 degrees celsius,” all by itself, is not meaningful information.

Facts
Here we have a weather report obtained by googling “weather in Kuala Lumpur.”
- The facts here are things like the temperature, humidity, probability of precipitation, and wind speed.
Notice that these are all quantities. But there are other facts here, such as the icon in the upper left corner of the image, which means “partly cloudy,” or the statement “Clear with periodic clouds,” and these other icons at the bottom of the image which indicate forecasted conditions, such as thundershowers.
All of these non-numeric facts are examples of qualitative facts. To make sense of these facts, we need to provide context.
Dimensions
Context is provided by dimensions, which includes things like the location, “Kuala Lumpur, Malaysia” and the day and time, “Tuesday at 3 a.m.” The statement “24°C in Kuala Lumpur, Malaysia on Tuesday, August 17th at 3:00 a.m.” means something.
Fact Table
A fact table typically consists of the facts of a business process, and it also contains foreign keys which establish well-defined links to dimension tables.
- Usually, facts are additive measures or metrics, such as dollar amounts for individual sales transactions.
- A fact table can contain detail level facts, such as individual sales transactions, or facts that have been aggregated, such as daily or weekly sales totals.
- Fact tables that contain aggregated facts are called summary tables.
Example
- You could summarize sales transactions by summing overall sales for each quarter of the year.
- An example of a foreign key might be ‘store ID.’
“Accumulating snapshot” fact tables are used to record events that take place during a well-defined business process.
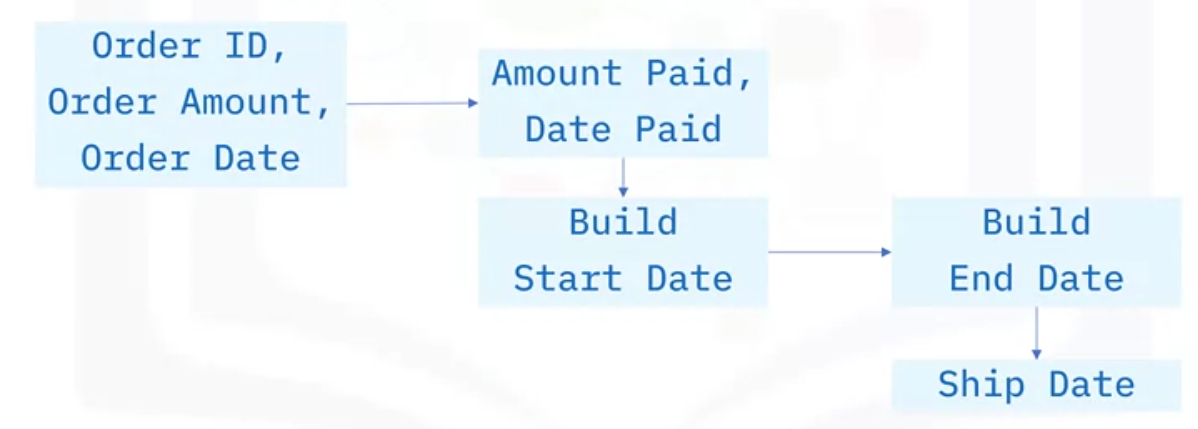
For example, suppose you have finished configuring a custom computer for yourself online, and you have just placed your order.
- The order date and the order amount are recorded in a snapshot table by the manufacturer.
- A unique “order ID” is also assigned.
- Once your order is verified, your payment is processed.
- The “amount paid” and the “date paid” are then recorded.
- After payment verification, the computer specifications are sent to the manufacturing department.
- Once the computer is in production, the “build start-date” is entered, and once the computer is built, the “build end-date” is recorded
- Finally, once your computer is ready to be sent, the “ship date” is recorded.
All these fields are stored in a single row of the table, which is uniquely identified by the “order ID.”
A dimension is a variable that categorizes facts:
- Dimensions are called “categorical variables” by statisticians and machine learning engineers.
- Dimensions enable users to answer business questions.
- The main uses for dimensions in analytics include filtering, grouping, and labeling operations.
Dimension Table
For example, commonly used dimensions include names of people, products, and places, and date or time stamps.
A dimension table thus stores the dimensions of a fact and is joined to the fact table via a foreign key.
Some examples of various types of dimension tables include:
- Product tables, which describe products, such as make, model, color, and size.
- Employee tables, which describe employees, such as name, title, and department.
- Temporal tables, which describe time at the level of granularity, or precision, at which events are recorded
- Geography tables, for location data such as country, state, city, and postal or zip code.
Example

Let us look at an example of a schema with both fact and dimension tables to help illustrate their relationships.
Fact Table:
- We could have a fact table for recording sales at a car dealership
- This table would store facts about each car sale such as the Sale date, and Sale amount as well as a primary key “Sale ID.”
- For each sales transaction, we also need to record its dimensions like the Vehicle sold and the Salesperson who sold it.
- The attributes of these dimensions, such as the vehicle Make and Model or the Salesperson’s First and Last name are stored in separate Vehicle and Salesperson tables
- However, we link them with the Sales table by recording the “Vehicle ID” and “Salesperson ID” as foreign keys in the Fact table.
- This way we typically end up with multiple dimension tables for each fact table.
DW Design - PostgreSQL
Here is a quick project which entails designing a DW for a cloud service provider.
Data
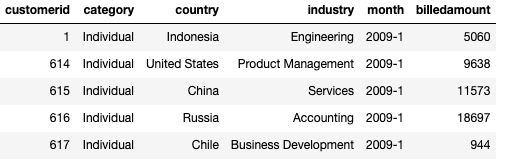
The cloud service provider has given us their billing data in the csv file cloud-billing-dataset.csv. This file contains the billing data for the past decade.
Here are the details of the billing data:
| Field Name | Details |
|---|---|
| customerid | Id of the customer |
| category | Category of the customer. Example: Individual or Company |
| country | Country of the customer |
| industry | Which domain/industry the customer belongs to. Example: Legal, Engineering |
| month | The billed month, stored as YYYY-MM. Example: 2009-01 refers to the month January in the year 2009 |
| billedamount | Amount charged by the cloud services provided for that month in USD |
Here is a sample of the data
Project
We need to design a data warehouse that can support the queries listed below:
- average billing per customer
- billing by country
- top 10 customers
- top 10 countries
- billing by industry
- billing by category
- billing by year
- billing by month
- billing by quarter
- average billing per industry per month
- average billing per industry per quarter
- average billing per country per quarter
- average billing per country per industry per quarter
Fact Table
Let’s design the Fact Tables, here is what we know:
The fact is the the bill which is generated monthly
- The fields customerid and billedamount are the important fields in the fact table
- We also need a way to identify the additional customer information other than the id and date
- It is obvious that a customer will have multiple bills so we need identify each bill separately for each customer, so we need a billid
- We also know that each month multiple customer will be getting a bill, so we need to be able to identify the month of each bill, so we need a monthid
- This way we can store dates in one table and tie that table to the fact table with monthid
- Store customer information in one table and tie that table to the fact table with billid
- And of course we can group the customer profile information in one table and tie that table to the fact table with customerid
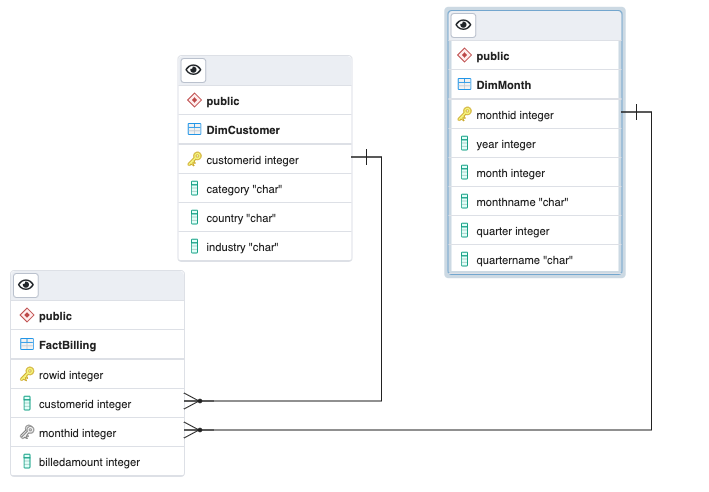
The final fact table for the bill would look like this:
| Field Name | Details |
|---|---|
| billid | Primary key - Unique identifier for every bill |
| customerid | Foreign Key - Id of the customer |
| monthid | Foreign Key - Id of the month. We can resolve the billed month info using this |
| billedamount | Amount charged by the cloud services provided for that month in USD |
Dimension Tables
If you look at the Fact table above, you notice that customerid and monthid are foreign keys and tie us to other tables and so we have two dimensions:
- customerid
- monthid
So let’s create those two tables:
| Field Name | Details |
|---|---|
| customerid | Primary Key - Id of the customer |
| category | Category of the customer. Example: Individual or Company |
| country | Country of the customer |
| industry | Which domain/industry the customer belongs to. Example: Legal, Engineering |
Looking at the tasks needed to be accomplished, we need to create some additional attributes that will help us solve the queries we’ll be conducting on a regular basis:
| Field Name | Details |
|---|---|
| monthid | Primary Key - Id of the month |
| year | Year derived from the month field of the original data. Example: 2010 |
| month | Month number derived from the month field of the original data. Example: 1, 2, 3 |
| monthname | Month name derived from the month field of the original data. Example: March |
| quarter | Quarter number derived from the month field of the original data. Example: 1, 2, 3, 4 |
| quartername | Quarter name derived from the month field of the original data. Example: Q1, Q2, Q3, Q4 |
So we now have these 3 tables:
| Table Name | Type | Details |
|---|---|---|
| FactBilling | Fact | This table contains the billing amount, and the foreign keys to customer and month data |
| DimCustomer | Dimension | This table contains all the information related the customer |
| DimMonth | Dimension | This table contains all the information related the month of billing |
Star Schema
Now that we have the 3 tables we can arrange them in Star Schema style and we get
DW Example - PostgreSQL
Create Schema on DW
- Start the PostgreSQL
Create DB
- First command will set my password for authentication
- create a db named: billingDW
- -h mentions that the database server is accessible using the hostname “postgres”
- -U mentions that we are using the user name postgres to log into the database
- -p mentions that the database server is running on port number 5432
$ wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0260EN-SkillsNetwork/labs/Working%20with%20Facts%20and%20Dimension%20Tables/star-schema.sqlExecute Script Create Schema
$ psql -h postgres -U postgres -p 5432 billingDW < star-schema.sql
BEGIN
CREATE TABLE
CREATE TABLE
CREATE TABLE
ALTER TABLE
ALTER TABLE
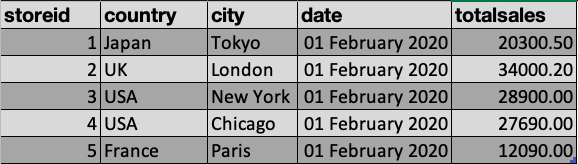
COMMITData
Here is a sample of the data
Fact Table
Similar to the billing example above, let’s design the fact table named: FactSales
- totalsales field will be captured in this table and we make sure
- we have a way to tie to details about each store so we use storeid
- and we need to tie to date details regarding each sale, so we use dateid
| Field Name | Details |
|---|---|
| rowid | Primary key - Unique identifier for every row |
| storeid | Foreign Key - Id of the store |
| dateid | Foreign Key - Id of the date |
| totalsales | Total sales |
Dimension Tables
I guess if you wish you can create the dimensions tables first, either way
- firstly we need to be able to extract the details for each store, so we use storeid as the pk and use it as the fk in the fact table
- secondly, we need to extract the granuality of a day, the details of the date, time, quarter… for each sale, so we use dateid as the pk in the dimension table and it’ll tie to the fact table as the fk
DimStore the store dimension table will look like this
| Field Name | Details |
|---|---|
| storeid | Primary key - Unique identifier for every store |
| city | City where the store is located. |
| country | Country where the store is located. |
DimDate table is
| Field Name | Details |
|---|---|
| dateid | Primary Key - Id of the date |
| day | Day derived from the date field of the original data. Example: 13, 19 |
| weekday | Weekday derived from the date field of the original data. Example: 1, 2, 3, 4, 5, 6, 7. 1 for sunday, 7 for saturday |
| weekdayname | Weekday name derived from the date field of the original data. Example: Sunday, Monday |
| year | Year derived from the date field of the original data. Example: 2010 |
| month | Month number derived from the date field of the original data. Example: 1, 2, 3 |
| monthname | Month name derived from the date field of the original data. Example: March |
| quarter | Quarter number derived from the date field of the original data. Example: 1, 2, 3, 4 |
| quartername | Quarter name derived from the date field of the original data. Example: Q1, Q2, Q3, Q4 |