Data Warehouse Systems
A data warehouse is a system that aggregates data from one or more sources into a single, central, consistent data store to support various data analytics requirements.
- Data warehouse systems support data mining, including the application of artificial intelligence and machine learning
- Data transformation during the ETL process speeds front-end reporting, delivering critical information fast
- Data warehouses enable online analytical processing, known as OLAP, which provides fast, flexible, multidimensional data analysis for business intelligence and decision support applications.
- Traditionally, data warehouses have been hosted on-premises within enterprise data centers, initially on mainframes and then on Unix, Windows, and Linux systems.
Data warehouses enable organizations to centralize data from disparate data sources, such as transactional systems, operational databases, and flat files. Data integration, removing bad data, eliminating duplicates, and standardizing data create a single source of the truth that results in better data quality for analysis.
- A single source of truth empowers users to leverage all the company’s data and access that data more efficiently.
- In addition, separating database operations from data analytics generally improves data access performance, leading to faster business insights.
Most data warehouse systems are supported via one or more of three platforms.
- First are appliances, which are pre-integrated bundles of hardware and software that provide high performance for workloads and low maintenance overhead.
- Cloud deployments only, offering the benefits of cloud scalability and pay-per-use economics, and in many cases, deliver their data warehouses as fully managed services.
Appliance DW
Let’s begin with appliance data warehouse system solutions, such as
Oracle Exadata
- An organization can deploy this data warehouse solution as part of an on-premises installation or via Oracle Public Cloud.
- Oracle Exadata features built-in algorithms and runs all types of workloads, including OLTP, data warehouse analytics, in-memory analytics, and mixed workloads.
IBM Netezza
- You can deploy IBM Netezza on IBM Cloud, Amazon Web Services, Microsoft Azure, and private clouds using the IBM Cloud Pak for Data System.
- IBM Netezza is widely recognized for its data science and machine-learning enablement.
Cloud Based DW
Amazon Redshift
- Amazon RedShift uses Amazon Web Services-specific hardware and proprietary software in the cloud for
- accelerated data compression and encryption
- machine learning, and
- graph-optimization algorithms that automatically organize and store data.
Snowflake
- Snowflake offers a multi-cloud analytics solution that complies with GDPR and CCPA data privacy regulations.
- Always-on encryption of data in transit and at rest.
- Snowflake is FedRAMP Moderate authorized.
Google BigQuery
- BigQuery describes its data warehouse system as a “flexible, multi-cloud data warehouse solution.”
- Google reports data warehouse uptime of 99.99% and
- Delivery of sub-second query response times from any business intelligence tool.
- Google BigQuery’s system specifies petabyte speed and massive concurrency to deliver real-time analytics.
Cloud & On-Premises DW
Microsoft Azure
- Microsoft Azure Synapse Analytics offers code-free visual ETL/ELT processes to ingest data from more than 95 native connectors.
- Azure Synapse Analytics supports data lake and data warehouse use cases and supports the use of T-SQL, Python, Scala, Spark SQL, and dot Net for both serverless and dedicated resources.
Teradata Vantage
- Teradata Vantage takes a slightly different approach. Teradata Vantage advertises its multi-cloud data platform for enterprise analytics that
- unifies data lakes, data warehouses, analytics, and new data sources and types.
- Teradata Vantage combines open source and commercial technologies to operationalize insights and delivers performance for mixed workloads with high query concurrency using workload management and adaptive optimization.
- For support, Teradata provides a single point of contact for operational task services including monitoring, change requests, performance tuning, security management, and reporting.
IBM Db2
- Recognized for its scalability, massively parallel processing capabilities, petaflop speeds, security features, and 99.99% service uptime.
- Provides a containerized scale-out data warehousing solution.
- You can move workloads where needed, including the public cloud, private cloud, or on-premises–with minimal or no changes required.
Vertica
- Vertica, another known hybrid-cloud data warehouse system, provides multi-cloud support for Amazon Web Services, Google, Microsoft Azure, and on-premises Linux hardware.
- Vertica reports fast multi-GB data transfer rates, scalable, elastic compute and storage, and notable system fault tolerance when using Eon mode.
Oracle Autonomous
- Oracle Autonomous Data Warehouse runs in Oracle Public Cloud and on-premises with support for multi-model data and multiple workloads.
- Oracle describes its system as built to eliminate manual data management and reports that they provide extensive automated security features, including autonomous data encryption both at rest and in motion, protection of regulated data, security patch application, and threat detection.
Selection Criteria
Let’s look at the criteria businesses use to evaluate data warehouse systems, including features and capabilities, compatibility and implementation considerations, ease of use and skills, support considerations, and various costs.
Location
One of the primary data warehouse features, or consideration, for an organization is location. Data warehouses can exist on-premises, on appliances, and on one or more cloud locations.
- To select a location, organizations must balance multiple demands related to data ingestion, storage, and access.
- For some organizations, securing their data is their highest priority, requiring a mandatory on-premises solution.
- Multi-location businesses that grapple with data privacy requirements such as CCPA or GDPR need on-premises or geo-specific data warehouse locations.
Features & Capabilities
Every organization balances security and data privacy requirements with the need for speed that delivers critical, profit-producing business insights. Organizations will also want to consider features and capabilities related to architecture and structure.
- Is the organization ready to commit to a vendor-specific architecture?
- Does the organization need multi-cloud installation such as multiple data warehouses in multiple locations?
- Does the solution scale to meet anticipated future needs?
- What data types are supported and what types of data does the organization ingest?
- If your organization currently analyzes dark data or is planning for the implementation of using semi-structured and unstructured data, you’ll want a data warehouse system that supports these data types.
- An organization that processes big data needs a system that supports both batch and streaming data.
- Capabilities that affectthe ease of implementation include data governance, data migration, and data transformation capabilities.
User Management
With the data warehouse system in place, how easily can the organization optimize and reoptimize system performance as needs change? Another consideration is user management, or ease of use:
- With more organizations implementing a zero-trust security policy because of expensive data breaches, implementing programs that manage and validate system users is mandatory.
- And notifications and reports are essential for organizations to correct errors and mitigate risks before minor issues become larger problems.
- Let’s explore ease of use and skills.
- Does your organization’s staff have the skills needed to implement a specific data warehousing vendor’s technology, and if not, how quickly and easily can they gain those skills?
- Complex, large data warehouse deployments can require additional work from your implementation partner, so their expertise also greatly matters.
- Finally, do the technology and engineering staff who architect, deploy, and administer front-end querying, reporting, and visualization tools have the skills needed to configure your new system quickly?
Support
- Support is essential and can become frustrating and expensive if not well planned for.
- You might find that by using a single vendor, you can leverage one highly accountable, responsible source, potentially saving you time, money, and frustration.
- You’ll also want to verify the availability of service level agreements for uptime, security, scalability, and other data warehouse system issues.
- Validate the vendor’s support hours and channels, such as by phone, email, chat, or text.
- Does the vendor offer self-service solutions and an active rich user community?
Total Cost
Consider the total cost of ownership, or TCO, for running systems for several years.
TCO includes:
- Infrastructure such as compute and storage costs – whether on-premises or on cloud;
- Software licensing, or in case of cloud offerings, their subscription or usage costs;
- Data migration and integration costs for moving data into the warehouse and pruning and purging as required;
- Administration costs for personnel to manage the systems and to train them; and
- Recurring support and maintenance costs paid to the warehousing vendor or implementation partner.
IBM Db2 Warehouse
IBM Db2 Warehouse is a complete data warehouse solution that offers a high level of control over your data and applications.
- Db2 Warehouse is easy to deploy within containerized environments such as Docker.
- Db2 Warehouse is a highly flexible data warehouse for client-managed, on-premises, cloud, and hybrid environments, that scales automatically with Massively Parallel Processing, known as MPP, to support containerized deployments.
- Db2 Warehouse comes pre-packaged with access to machine learning algorithms and utilizes in-database business analytics for speed.
- Db2 Warehouse enables you to automatically generate data schemas, and seamlessly transform and load unstructured data sources into a structured format for analysis.
- Db2 Warehouse speeds queries using BLU Acceleration, which includes in-memory SQL columnar processing, data-skipping; and, as mentioned before, a Massively Parallel Processor cluster architecture that speeds complex queries.
- Db2 Warehouse supports your AI analytics needs.
- Db2 Warehouse comes with dashboards for monitoring performance and reporting issues.
- Some of the use cases that Db2 Warehouse is well-suited for include:
- Elasticity, or high-scalability requirements
- Cloud, on-premises, or hybrid hosting
- Consolidation and integration of disparate data sources
- Rapid development of line-of-business analytics products, such as data marts
- Management of sensitive or regulated data; and
- Storage of older, colder structured SQL data.
- Db2 Warehouse supports a range of clients and plugins, including:
- Java Database Connectivity,
- or JDBC,
- Node.JS,
- Spring,
- Python,
- R,
- Go,
- Spark, and
- Microsoft Visual Studio.
- IBM Db2 Warehouse, with its integrated Apache Spark cluster, can be partitioned and deployed across a cluster of machines.
- You can use R Studio to analyze, wrangle, model, and visualize your data with Db2 Warehouse.
- You can even develop applications that run R code, integrated with Db2 through a REST API.
- Db2 Warehouse also has a range of commonly used open source drivers available on GitHub in the “IBM DB” repository.
- For example, under “popular repositories,” you can find the “python-ibmdb” package, which provides a Python interface for connecting to IBM DB2
Data Marts
A data mart is an isolated part of the larger enterprise data warehouse that is specifically built to serve a particular business function, purpose, or community of users. Data marts are designed to provide specific support for making tactical decisions. As such, data marts are focused only on the most relevant data, which saves end users the time and effort that would otherwise be spent searching the data warehouse for insights.
For example:
- The sales and finance departments in a company may have access to dedicated data marts that supply the data required for their quarterly sales reports and projections
- The marketing team may use data marts to analyze customer behavior data, and the shipping, manufacturing and warranty departments may have their own data marts.
Structure
The typical structure of a data mart is as follows:
- It is a relational database with a star, or more often a snowflake schema, which means it contains a central fact table consisting of the business metrics relevant to a business process, which is
- surrounded by a related hierarchy of dimension tables that provide context for the facts.
Let’s look at some typical differences between three types of data repositories:
- data marts,
- transactional databases
- data warehouses
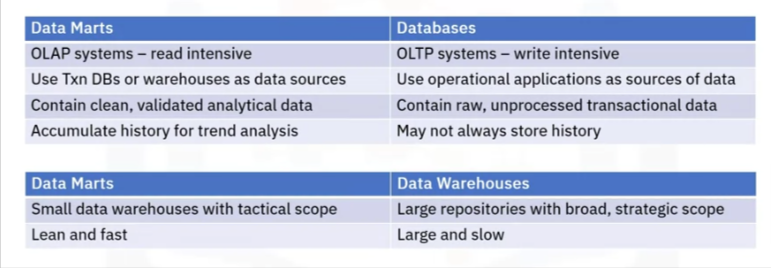
- Both data marts and data warehouses are online analytical processing (or OLAP) systems that are optimized for read-intensive queries and operations, whereas
- transactional databases are online transaction processing (or OLTP) systems that are optimized for write-intensive queries and applications.
- Data marts use transactional databases or data warehouses as data sources, while in transactional databases, operational applications, such as point-of-sales systems, serve as the sources of data.
- Data marts accumulate historical data that can be used for trend analysis, while transactional databases may not always store older data.
- A data mart is much like a data warehouse, except it has a smaller, tactical scope.
- Data warehouses broadly support the strategic requirements of the enterprise.
- Data marts are lean and fast compared to data warehouses, which can be very large, and hence, can be slower.
A data mart stores validated, transformed, and cleaned data, while a database will have raw data that has not yet been cleaned.
There are three basic types of data marts—dependent, independent, and hybrid. The difference between these three kinds of data marts depends on their relationship with the data warehouse and the sources used for supplying each of them with data.
- Dependent data marts draw data from the enterprise data warehouse
- Offer analytical capabilities within a restricted area of the enterprise data warehouse
- They inherit the security that comes with the enterprise data warehouse and since dependent data marts pull data directly from the data warehouse, where data has already been cleaned and transformed, they
- Tend to have simpler data pipelines than independent data marts.
- Independent data marts bypass the data warehouse and are created directly from sources, which may include internal operational systems or external data from vendors or other sources outside the enterprise.
- They require custom extract, transform and load data pipelines to carry out the transformation and integration processes on the source data since it is coming directly from operational systems and external sources
- May also require separate security measures.
- Hybrid data marts only depend partially on the enterprise data warehouse. They combine inputs from data warehouses with data from operational systems and other systems external to the warehouse.
Data Lakes
A data lake is a storage repository that can store large amounts of structured, semi-structured, and unstructured data in their native format, classified and tagged with metadata. While a data warehouse stores data processed for a specific need, a data lake is a pool of raw data where each data element is given a unique identifier and is tagged with metatags for further use.
You would opt for a data lake if you generate, or have access to, large amounts of data on an ongoing basis but don’t want to be restricted to specific or pre-defined use cases.
Data lakes are sometimes also used as a staging area for transforming data prior to loading into a data warehouse or a data mart.
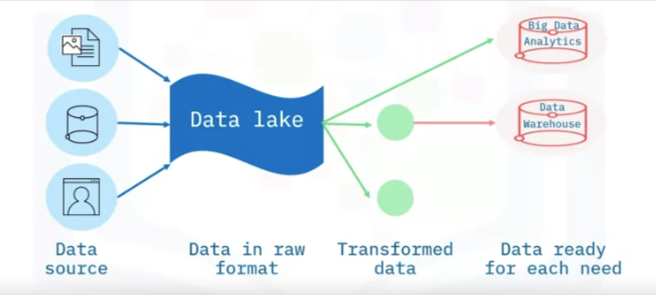
- A data lake is a data repository that can store a large amount of structured, semi-structured and unstructured data in its native format.
- You do not need to define the structure and schema of data before loading the data into the data lake.
- You do not even need to know all the use cases for which you will be analyzing the data.
- A data lake exists as a repository of raw data, straight from the source to be transformed based on the use case for which it needs to be analyzed, which does not mean that a data lake is a place where data can be dumped without governance.
- Data lakes can be deployed using cloud object storage, such as Amazon S3. Or, large-scale distributed systems such as Apache Hadoop, used for processing Big Data.
- You can deploy data lakes on relational database management systems, as well as NoSQL data repositories that can store very large amounts of data.
Data lakes offer a number of benefits:
- Data lakes can store all types of data includingunstructured data, such as documents and emails semi-structured data, such as JSON and XML files, and structured data from relational databases.
- Scalability is another data lake benefit. Data lakes can make use of scalable storage capacity—from terabytes to petabytes of data. By retaining data in its original format, data lakes save organizations time that would have been used to define structures, create schemas, and transform the data.
- The ability to access data in its original format enables fast, flexible reuse of the data for a wide range of current and future use cases.
Some of the vendors that provide technologies, platforms, and reference architectures for data lakes include:
- Amazon
- Cloudera
- IBM
- Informatica
- Microsoft
- Oracle
- SAS
- Snowflake
- Teradata
- And, Zaloni.
All in all, data lakes were designed in response to the limitations of data warehouses. Depending on the requirements, a typical organization will require both a data warehouse and a data lake as they serve different needs.
Let’s compare data lakes with data warehouses:
- When it comes to data, in a data lake, data is integrated in its raw and unstructured form.
- A data warehouse is different.
- Talking about schema, when using data lakes, you do not need to define the structure and schema of the data before loading into the data lake.
- A data warehouse on the other hand requires strict conformance to schema and therefore a schema needs to be designed and implemented prior to loading the data.
- In data lakes the data might or might not be curated, for example raw data. And data is agile and does not necessarily comply with governance guidelines.
- In comparison, the data in data warehouses is curated and adheres to data governance.
Data scientists, data developers, and machine learning engineers are the typical users of data lakes.
Data warehouses, on the other hand, are mainly used by business analysts, and data analysts.
Data Lakehouses
A data lakehouse is a hybrid data architecture that combines the benefits of both data warehouses and data lakes. It provides a single platform for storing, managing, and analyzing both structured and unstructured data, offering a flexible and scalable solution for big data analytics.
Key Characteristics:
Combines data warehouse and data lake features: Data lakehouses implement data warehouse-like data structures and management features on top of a data lake, enabling both business intelligence (BI) and advanced analytics (machine learning, predictive analytics, etc.).
Low-cost, flexible storage: Data lakehouses leverage the cost-effective and scalable storage capabilities of data lakes, making it suitable for large volumes of diverse data.
Data structures and management features: Data lakehouses incorporate data warehouse-like features, such as schema enforcement, data validation, and ACID-compliant transactions, ensuring data quality and integrity.
Metadata layers: Intelligent metadata layers, like Delta Lake, track file versions, schema evolution, and data validation, enabling rich management features and supporting advanced analytics.
Single platform: Data lakehouses consolidate multiple data platforms, eliminating the need for separate data warehouses and data lakes, and reducing operational expenses.
Benefits:
Unified analytics: Data lakehouses enable data analysts and scientists to access and analyze all data types (structured, unstructured, and semi-structured) in a single platform.
Faster time-to-insight: By eliminating data duplication and providing a single source of truth, data lakehouses accelerate analytics and reduce data latency.
Improved data governance: Data lakehouses automate compliance procedures and provide robust data management features, ensuring data quality and security.
Scalability and flexibility: Data lakehouses can handle large volumes of data and scale horizontally, making them suitable for big data analytics and AI/ML workloads.
Cost-effective: Data lakehouses reduce operational expenses by consolidating multiple data platforms and leveraging low-cost storage.
Real-World Applications:
Business intelligence: Data lakehouses support traditional BI applications, such as reporting and dashboarding, while also enabling advanced analytics.
Machine learning: Data lakehouses provide a single platform for data scientists to develop and deploy machine learning models, leveraging both structured and unstructured data.
Predictive analytics: Data lakehouses enable organizations to build predictive models and perform advanced analytics on large datasets, driving business insights and decision-making.
IBM Watsonx
IBM Watsonx.data is crafted to address the challenges enterprises face in managing vast volumes of data while attempting to harness this data for AI-driven insights. The platform is built on a lakehouse architecture, which uniquely combines the scalability and flexibility of data lakes with the management features and performance of data warehouses. This architecture allows organizations to store all their data in a single, unified repository that supports both machine learning and BI workloads effectively.
Key Features
Unified Data Platform: Watsonx.data integrates various types of data, from structured to unstructured, in a single platform. This integration enables seamless data management and analysis, eliminating the silos that typically complicate data accessibility and quality.
Built for Scale: Leveraging cloud-native technologies, IBM Watsonx.data is designed to scale horizontally, supporting an increase in data volume without sacrificing performance. This scalability ensures that enterprises can manage growing data needs efficiently.
Optimized for AI and Analytics: The platform is optimized for high-performance analytics and AI workloads. It includes built-in support for popular data science tools and languages, allowing data scientists and analysts to work with the tools they are already familiar with.
Advanced Data Governance and Security: Watsonx.data provides robust governance capabilities, ensuring that data across the platform is well-managed, secure, and compliant with various regulatory requirements. This feature is crucial for enterprises that deal with sensitive or regulated data.
Open and Interoperable: By supporting open data formats and integrating with various data processing frameworks, Watsonx.data ensures that enterprises are not locked into a single vendor or technology. This openness fosters innovation and flexibility in developing data-driven solutions.
Benefits
Enhanced Data Accessibility: By centralizing data in a single platform, Watsonx.data makes it easier for users across the organization to access the data they need when they need it. This accessibility accelerates data-driven decision-making processes.
Cost Efficiency: The lakehouse architecture reduces the need for duplicating data across multiple data storage systems, which can significantly lower storage costs and simplify the IT landscape.
Improved Data Quality and Insights: With advanced governance tools and a unified data repository, Watsonx.data helps improve the quality of data. Better data quality leads to more accurate analytics and AI models, enhancing the insights that businesses can derive.
Use Cases
Financial Services: In the financial sector, Watsonx.data can be used to improve risk analysis by integrating and analyzing transaction data in real-time, helping to detect potential fraud and adjust risk models more swiftly.
Healthcare: For healthcare providers, Watsonx.data can centralize patient records and research data, facilitating more personalized medicine approaches and speeding up research on treatment effectiveness.
Retail: Retailers can use Watsonx.data to combine customer data, inventory data, and supplier data to optimize supply chains, personalize marketing efforts, and enhance customer service.
Conclusion
IBM Watsonx.data is at the forefront of the next generation of data management solutions, designed to empower organizations to leverage their data fully in the pursuit of transformative, AI-driven outcomes. By providing a scalable, secure, and efficient platform, IBM Watsonx.data not only simplifies the technical challenges of data management but also unlocks new opportunities for innovation and growth. As businesses continue to navigate the complexities of digital transformation, solutions like Watsonx.data will play a pivotal role in defining the future of enterprise data analytics.