export PGPASSWORD=ddd;
# Create db
createdb -h postgres -U postgres -p 5432 billingDWExtract Schema from Script
Staging Areas
What is a data warehouse staging area?
You can think of a staging area as an intermediate storage area that is used for ETL processing. Thus, staging areas act as a bridge between data sources and the target data warehouses, data marts, or other data repos.
- They are often transient, meaning that they are erased after successfully running ETL workflows.
- However, many architectures hold data for archival or troubleshooting purposes.
- They are also useful for monitoring and optimizing your ETL workflows.
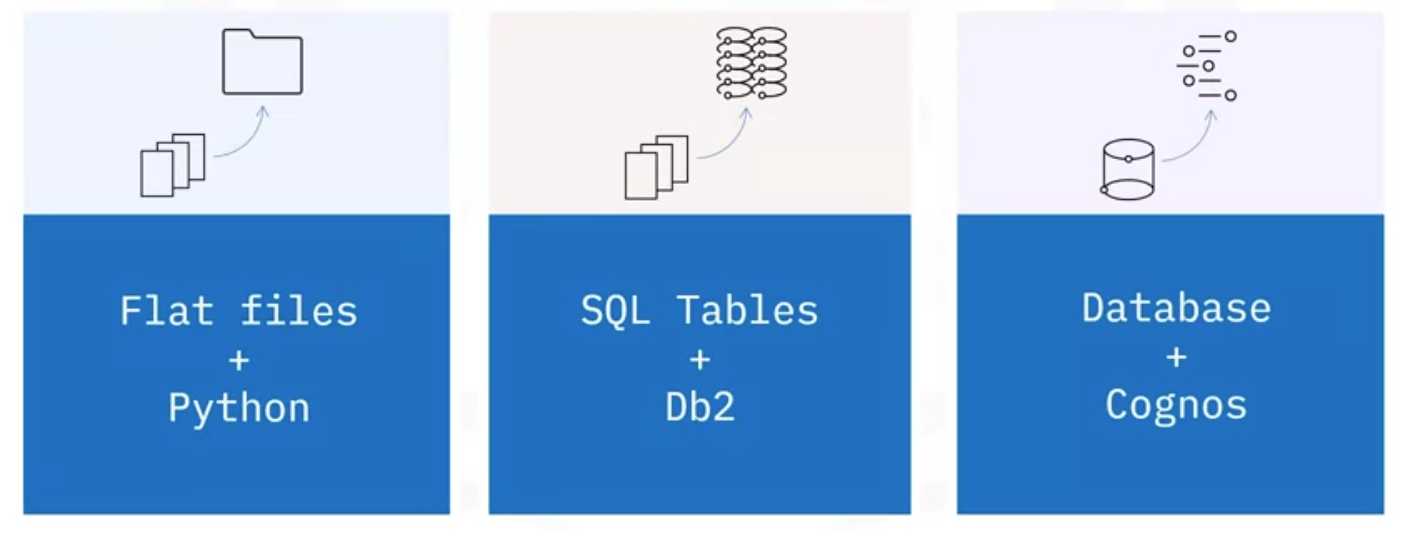
Implementation
Staging areas can be implemented in many ways, including:
- simple flat files, such as csv files, stored in a directory, and managed using tools such as Bash or Python, or
- a set of SQL tables in a relational database such as Db2, or
- a self-contained database instance within a data warehousing or business intelligence platform such as Cognos Analytics.
Example: Let’s explore an example use case, to illustrate a possible architecture for a Data Warehouse containing a Staging Area, which in turn includes an associated Staging Database.
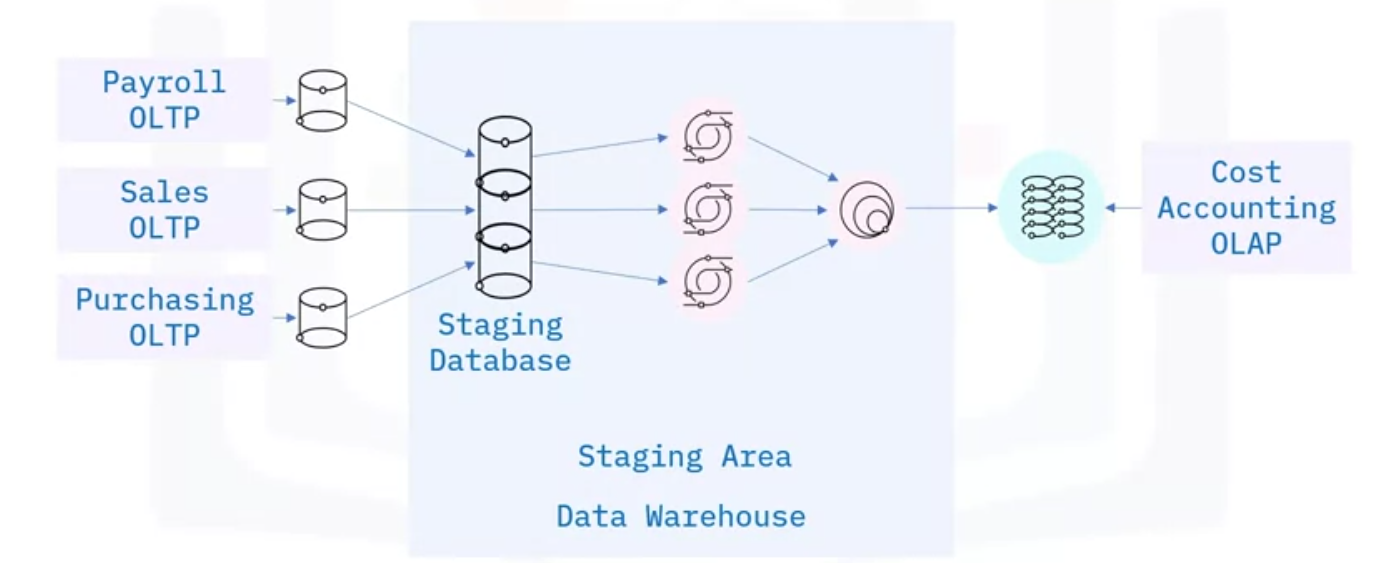
Imagine the enterprise would like to create a dedicated “Cost Accounting” Online Analytical Processing system.
- The required data is managed in separate Online Transaction Processing Systems within the enterprise, from the Payroll, Sales, and Purchasing departments.
- From these siloed systems, the data is extracted to individual Staging Tables, which are created in the Staging Database.
- Data from these tables is then transformed in the Staging Area using SQL to conform it to the requirements of the Cost Accounting system.
- The conformed tables can now be integrated, or joined, into a single table.
- The final phase is the loading phase, where the data is loaded into the target cost-accounting system.
Function
A staging area can have many functions. Some typical ones include:
- Integration: Indeed, one of the primary functions performed by a staging area is consolidation of data from multiple source systems.
- Change detection: Staging areas can be set up to manage extraction of new and modified data as needed.
- Scheduling: Individual tasks within an ETL workflow can be scheduled to run in a specific sequence, concurrently, and at certain times.
- Data cleansing and validation. For example, you can handle missing values and duplicated records.
- Aggregating data: You can use the staging area to summarize data. For example, daily sales data can be aggregated into weekly, monthly, or annual averages, prior to loading into a reporting system.
- Normalizing data: To enforce consistency of data types, or names of categories such as country and state codes in place of mixed naming conventions such as “Mont,” “MA,” or “Montana.”
Purpose
- A staging area is a separate location, where data from source systems is extracted to.
- The extraction step therefore decouples operations such as validation, cleansing and other processes from the source environment.
- This helps to minimize any risk of corrupting source-data systems, and
- Simplifies ETL workflow construction, operation, and maintenance.
- If any of the extracted data becomes corrupted somehow, you can easily recover.
PostgreSQL Staging Area -1
Let’s run through a quick example on how to:
- Setup a staging server for a data warehouse
- Create the schema to store the data
- Load the data into the tables
- Run a sample query
- Our instance will be on the cloud
Start PostgreSQL Server
Create DB
- Now, open a new terminal, by clicking on the menu bar and selecting Terminal->New Terminal. This will open a new terminal at the bottom of the screen.
- First export your PostgreSQL server password in the below command and execute it.
- Create db with the second command
- As explained in other pages:
-hmentions that the database server is accessible using the hostname “postgres”-Umentions that we are using the user name postgres to log into the database-pmentions that the database server is running on port number 5432
- The commands to create the schema are available in the file below. https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0260EN-SkillsNetwork/labs/Setting%20up%20a%20staging%20area/billing-datawarehouse.tgz
- Run the commands below to download and extract the schema files.
wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-DB0260EN-SkillsNetwork/labs/Setting%20up%20a%20staging%20area/billing-datawarehouse.tgz
tar -xvzf billing-datawarehouse.tgz
ls *.sql
# OUTPUT
saved [944578/944578]
DimCustomer.sql
DimMonth.sql
FactBilling.sql
star-schema.sql
verify.sql
DimCustomer.sql FactBilling.sql verify.sql
DimMonth.sql star-schema.sqlCreate Schema from Srcipt
$ psql -h postgres -U postgres -p 5432 billingDW < star-schema.sql
BEGIN
CREATE TABLE
CREATE TABLE
CREATE TABLE
ALTER TABLE
ALTER TABLE
COMMITPopulate Dimension Tables
- Load the data into dimension table DimCustomer
$ psql -h postgres -U postgres -p 5432 billingDW < DimCustomer.sql
INSERT 0 1000- Load data into dimension table DimMonth
$ psql -h postgres -U postgres -p 5432 billingDW < DimMonth.sql
INSERT 0 132Populate Fact Table
- Finally, load data into fact table FactBilling
$ psql -h postgres -U postgres -p 5432 billingDW < FactBilling.sql
INSERT 0 132000Run Sample Query
- Check the number of rows in all the tables by running a query
$ psql -h postgres -U postgres -p 5432 billingDW < verify.sql
"Checking row in DimMonth Table"
count
-------
132
(1 row)
"Checking row in DimCustomer Table"
count
-------
1000
(1 row)
"Checking row in FactBilling Table"
count
--------
132000
(1 row)PostgreSQL Staging Area - 2
Create a db: practice and load data into it as we just did above, the steps will be outlined in the chunk of code below:
# Export password
$ export PGPASSWORD=ddd;
# Create db
$ createdb -h postgres -U postgres -p 5432 practice
# Create schema using Script file
$ psql -h postgres -U postgres -p 5432 practice < star-schema.sql
BEGIN
CREATE TABLE
CREATE TABLE
CREATE TABLE
ALTER TABLE
ALTER TABLE
COMMIT
# Load data into all 3 tables
$ psql -h postgres -U postgres -p 5432 practice < DimMonth.sql
$ psql -h postgres -U postgres -p 5432 practice < DimCustomer.sql
$ psql -h postgres -U postgres -p 5432 practice < FactBilling.sql
INSERT 0 132
INSERT 0 1000
INSERT 0 132000
# Verify we loaded all the rows by running a query in the script file - output matches above
$ psql -h postgres -U postgres -p 5432 practice < verify.sql
"Checking row in DimMonth Table"
count
-------
132
(1 row)
"Checking row in DimCustomer Table"
count
-------
1000
(1 row)
"Checking row in FactBilling Table"
count
--------
132000
(1 row)