# List of fields in MyDimDate
dateid
date
year
quarter
quartername
month
monthname
day
weekday
weekdaynameMyDimWaste - T2
Create DW for Solid Waste Co
In this project we’ll:
Develop dimension and fact tables to organize and structure data for analysis -> Design a DW
Employ SQL queries to create and load data into dimension and fact tables
Create materialized views to optimize query performance
Scenario
You are a data engineer hired by a solid waste management company. The company collects and recycles solid waste across major cities in the country of Brazil. The company operates hundreds of trucks of different types to collect and transport solid waste. The company would like to create a data warehouse so that it can create reports like:
- Total waste collected per year per city
- Total waste collected per month per city
- Total waste collected per quarter per city
- Total waste collected per year per truck type
- Total waste collected per truck type per city
- Total waste collected per truck type per station per city
Tasks
We’ll perform the following tasks using our understanding of dimensional modeling, SQL querying, and data warehousing concepts:
Task 1: Design the dimension table MyDimDate
Task 2: Design the dimension table MyDimWaste
Task 3: Design the dimension table MyDimZone
Task 4: Design the fact table MyFactTrips
Task 5: Create the dimension table MyDimDate
Task 6: Create the dimension table MyDimWaste
Task 7: Create the dimension table MyDimZone
Task 8: Create the fact table MyFactTrips
Task 9: Load data into the dimension table DimDate
Task 10: Load data into the dimension table DimTruck
Task 11: Load data into the dimension table DimStation
Task 12: Load data into the fact table FactTrips
Task 13: Create a grouping sets query
Task 14: Create a rollup query
Task 15: Create a cube query using the columns year, city, station, and average waste collected
Task 16: Create a materialized view named max_waste_per_station using the columns city, station, trucktype, and max waste collected
Design Star Schema DW
Data
Here is a partial view of the data provided:

MyDimDate - T1
Write down the fields in the MyDimDate table. The company is looking at a granularity of day, which means they would like to have the ability to generate the report on a yearly, monthly, daily, and weekday basis.
Write down the fields in the MyDimWaste table
# List of fields in MyDimWaste
wastetypeid
wastetypeMyDimZone - T3
Write down the fields in the MyDimZone table
# List of fields in MyDimZone
zoneid
zonename
cityMyFactTrips - T4
Task 4: Design the fact table MyFactTrips
Write down the fields in the MyFactTrips table
# List of fields in MyFactTrips
tripid
wastetypeid
zoneid
dateid
wastecollectedCreate Tables Schema
We will use PostgreSQL and in particular, pgAdmin and create a database named Project, then create the following tables.
MyDimDate - T5
CREATE TABLE MyDimDate (
dateid INT PRIMARY KEY,
date DATE NOT NULL,
year INT NOT NULL,
quarter INT NOT NULL,
quarterName VARCHAR(2) NOT NULL,
month INT NOT NULL,
monthname VARCHAR(9) NOT NULL,
day INT NOT NULL,
weekday INT NOT NULL,
weekdayName VARCHAR(9) NOT NULL
);MyDimWaste - T6
CREATE TABLE MyDimWaste (
wasteid INT PRIMARY KEY,
wastetype VARCHAR(15) NOT NULL
);MyDimZone - T7
CREATE TABLE MyDimZone (
zoneid INT PRIMARY KEY,
zonename VARCHAR(25) NOT NULL,
city VARCHAR(15) NOT NULL
);MyFactTrips - T8
CREATE TABLE MyFactTrips (
tripid INT PRIMARY KEY,
wastetypeid INT NOT NULL,
zoneid INT NOT NULL,
dateid INT NOT NULL,
wastecollected FLOAT NOT NULL,
FOREIGN KEY (wasteid) REFERENCES MyDimWaste(wasteid),
FOREIGN KEY (zoneid) REFERENCES MyDimZone(zoneid),
FOREIGN KEY (dateid) REFERENCES MyDimDate(dateid)
);Change Schema
After the initial schema design, you were told that due to operational issues, data could not be collected in the format initially planned. This implies that the previous tables (MyDimDate, MyDimWaste, MyDimZone, MyFactTrips) in the Project database and their associated attributes are no longer applicable to the current design. The company has now provided data in CSV files with new tables DimTruck and DimStation as per the new design.
Data
- You will need to load the data provided by the company in CSV format.
- First, create a new database named FinalProject.
- Then, create the tables DimDate, DimTruck, DimStation, and FactTrips by defining the structure of the columns as per the CSV files.
- Next, load the data from the CSV files into the appropriate tables.
Note: Ensure that you upload the files to this path: /var/lib/pgadmin/
Recreate & Populate
DimDate - T9
Based on the data in the csv file, here is the new schema and query to create the table, view first 5 rows
CREATE TABLE DimDate (
dateid INT PRIMARY KEY,
date DATE NOT NULL,
Year INT NOT NULL,
Quarter INT NOT NULL,
QuarterName VARCHAR(2) NOT NULL,
Month INT NOT NULL,
Monthname VARCHAR(255) NOT NULL,
Day INT NOT NULL,
Weekday INT NOT NULL,
WeekdayName VARCHAR(255) NOT NULL
);
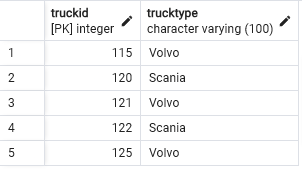
DimTruck -T10
Based on the data in the csv file, here is the new schema and query to create the table, view first 5 rows
CREATE TABLE DimTruck (
Truckid INT PRIMARY KEY,
TruckType VARCHAR(100) NOT NULL
);
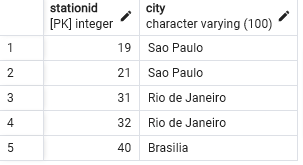
DimStation - T11
Based on the data in the csv file, here is the new schema and query to create the table, view first 5 rows
CREATE TABLE DimStation (
Stationid INT PRIMARY KEY,
city VARCHAR(100) NOT NULL
);
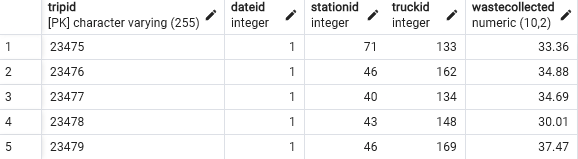
FactTrips - T12
Based on the data in the csv file, here is the new schema and query to create the table, view first 5 rows
CREATE TABLE FactTrips (
Tripid VARCHAR(255) PRIMARY KEY,
Dateid INT NOT NULL,
Stationid INT NOT NULL,
Truckid INT NOT NULL,
Wastecollected DECIMAL(10, 2) NOT NULL,
FOREIGN KEY (Dateid) REFERENCES DimDate(dateid),
FOREIGN KEY (Stationid) REFERENCES DimStation(Stationid),
FOREIGN KEY (Truckid) REFERENCES DimTruck(Truckid)
);
Aggregation Queries
Grouping Sets - T13
Create a grouping sets query using the columns stationid, trucktype, total waste collected.
- We are joining FactTrips ‘f’ with DimStation ‘p’ on their stationid to correlate waste collected for each trucktype
- Output is 58 rows
- You see towards the end of the table you see a row for the entire group of Scania
- One row for the entire group of Volvo, both of which are the TruckType
- The rows of () are the grand total rows which doesn’t group by any Stationid but returns the sum for all Stationids
SELECT
f.Stationid,
t.TruckType,
SUM(f.Wastecollected) AS TotalWasteCollected
FROM
FactTrips f
INNER JOIN
DimTruck t ON f.Truckid = t.Truckid
GROUP BY GROUPING SETS (
(f.Stationid, t.TruckType),
f.Stationid,
t.TruckType,
()
)
ORDER BY
f.Stationid,
t.TruckType;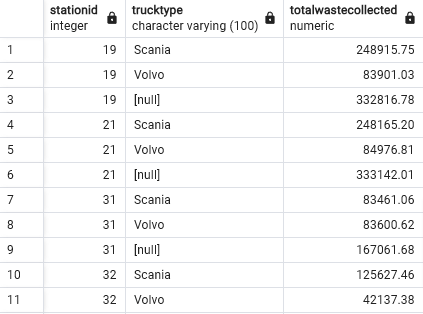
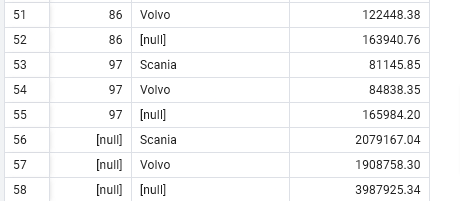
- To be more targeted and only group by the combination of the two use
- And we only get 37 rows
- Notice how we group by Stationid first then by TruckType
SELECT
f.Stationid,
t.TruckType,
SUM(f.Wastecollected) AS TotalWasteCollected
FROM
FactTrips f
INNER JOIN
DimTruck t ON f.Truckid = t.Truckid
GROUP BY GROUPING SETS (
(f.Stationid, t.TruckType),
()
)
ORDER BY
f.Stationid,
t.TruckType;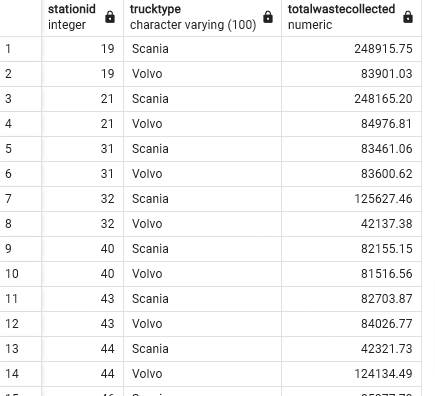
- If we don’t use the ORDER BY clause we get:
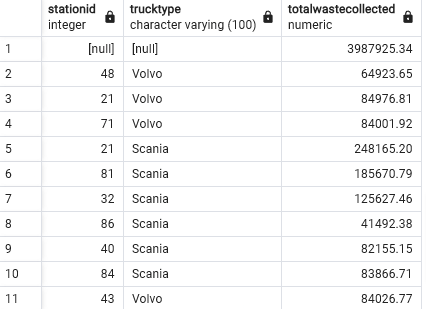
Rollup Query - T14
Create a rollup query using the columns year, city, stationid, and total waste collected.
- Table is 8751 rows
SELECT
d.dateid,
s.city,
f.Stationid,
SUM(f.Wastecollected) AS TotalWasteCollected
FROM
FactTrips f
JOIN
DimStation s ON f.Stationid = s.Stationid
JOIN
DimDate d ON f.dateid = d.dateid
GROUP BY
ROLLUP (d.dateid, d.year, s.city, f.stationid);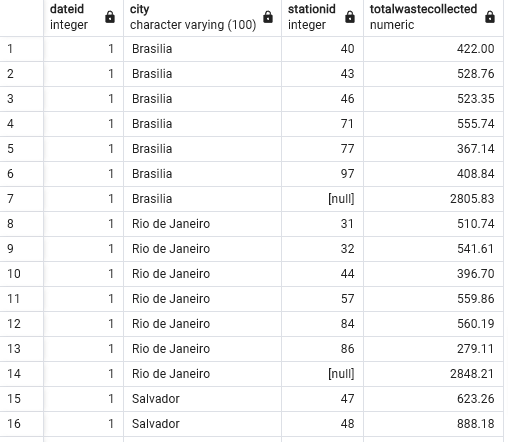
Cube Query - T15
Create a cube query using the columns year, city, stationid, and average waste collected.
- Output has 129 rows
SELECT
d.Year,
s.City,
f.Stationid,
AVG(f.wastecollected) AS AverageWasteCollected
FROM
FactTrips f
INNER JOIN
DimStation s ON f.Stationid = s.Stationid
INNER JOIN
DimDate d ON f.dateid = d.dateid
GROUP BY
CUBE (d.Year, s.City, f.Stationid);
Materialized View
Max_waste_stats
Create a materialized view named max_waste_stats using the columns city, stationid, trucktype, and max waste collected.
CREATE MATERIALIZED VIEW max_waste_stats AS
SELECT
s.City,
f.Stationid,
t.TruckType,
MAX(f.wastecollected) AS MaxWaste
FROM
FactTrips f
JOIN
DimStation s ON f.Stationid = s.Stationid
JOIN
DimTruck t ON f.Truckid = t.Truckid
GROUP BY
s.City,
f.Stationid,
t.TruckType
WITH DATA;
Refresh View
Refresh the view and print it out
REFRESH MATERIALIZED VIEW max_waste_stats;SELECT * FROM max_waste_stats;- Output is 36 rows