Star & Snowflake
Star Schema
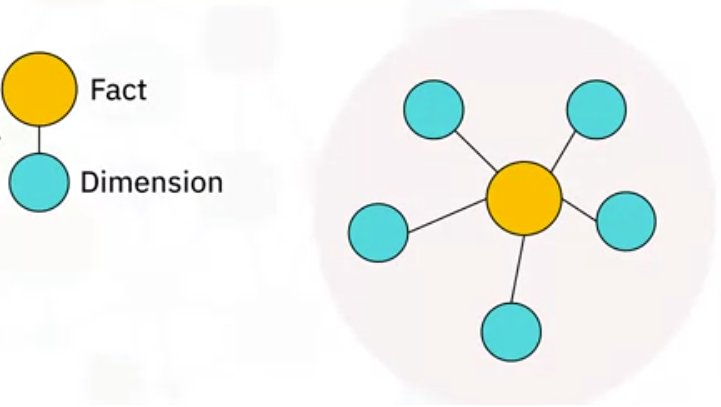
Recall that a fact table contains foreign keys that refer to the primary keys of dimension tables. The idea of a star schema is based on the way a set of dimension tables can be visualized, or modeled, as radiating from a central fact table, linked by these keys.
- A star schema is thus a graph, whose nodes are fact and dimension tables, and whose edges are the relations between those tables.
- Star schemas are commonly used to develop specialized data warehouses called “data marts.”
Snowflake Schema
Snowflake schemas are a generalization of star schemas and can be seen as normalized star schemas. Normalization means separating the levels or hierarchies of a dimension table into separate child tables.
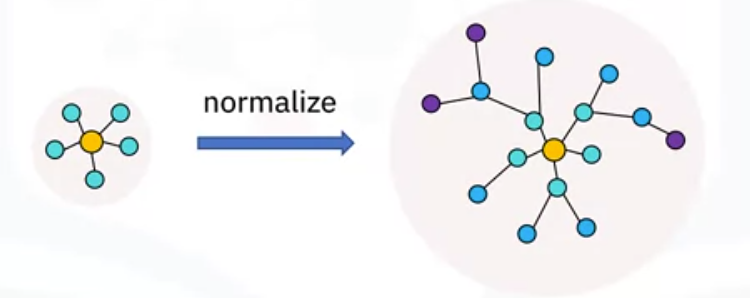
- A schema need not be fully normalized to be considered a snowflake, so long as at least one of its dimensions has its levels separated.
Let’s look at some general principles you need to consider when designing a data model for a star schema.
- The first step involves selecting a business process as the basis for what you want to model. You might be interested in processes such as sales, manufacturing, or supply chain logistics.
- In step two, you need to choose a granularity, which is the level of detail that you need to capture. Are you interested in coarse-grained information such as annual regional sales numbers? Or, maybe you want to drill down into monthly sales performance by salesperson.
- Next in the process, you need to identify the dimensions. These may include attributes such as the date and time, and names of people, places, and things.
- Identify the facts. These are the things being measured in the business process.
Example
Imagine, for example, that you are a data engineer helping to lay out the data ops for a new store called “A to Z Discount Warehouse.”
Dimensions
- They would like you to develop a data plan to capture everyday POS, or point-of-sales transactions that happen at the till, where customers have their items scanned and pay for them.
- Thus, “point-of-sale transactions” is the business process that you want to model.
- The finest granularity you can expect to capture from POS transactions comes from the individual line items, which is included in the detailed information you can see on a typical store receipt. This is precisely what “A to Z” is interested in capturing.
- The next step in the process is to identify the dimensions. These include attributes such as the date and time of the purchase, the store name, the products purchased, and the cashier who processed the items. You might add other dimensions, like “payment method,” whether the line item is a return or a purchase, and perhaps a “customer membership number.”
Star Schema
Facts Table
- Now it’s time to consider the facts. Thus, you identify facts such as the amount for each item’s price, the quantity of each product sold, any discounts applied to the sale, and the sales tax applied.
- Other facts to consider include environmental fees, or deposit fees for returnable containers.
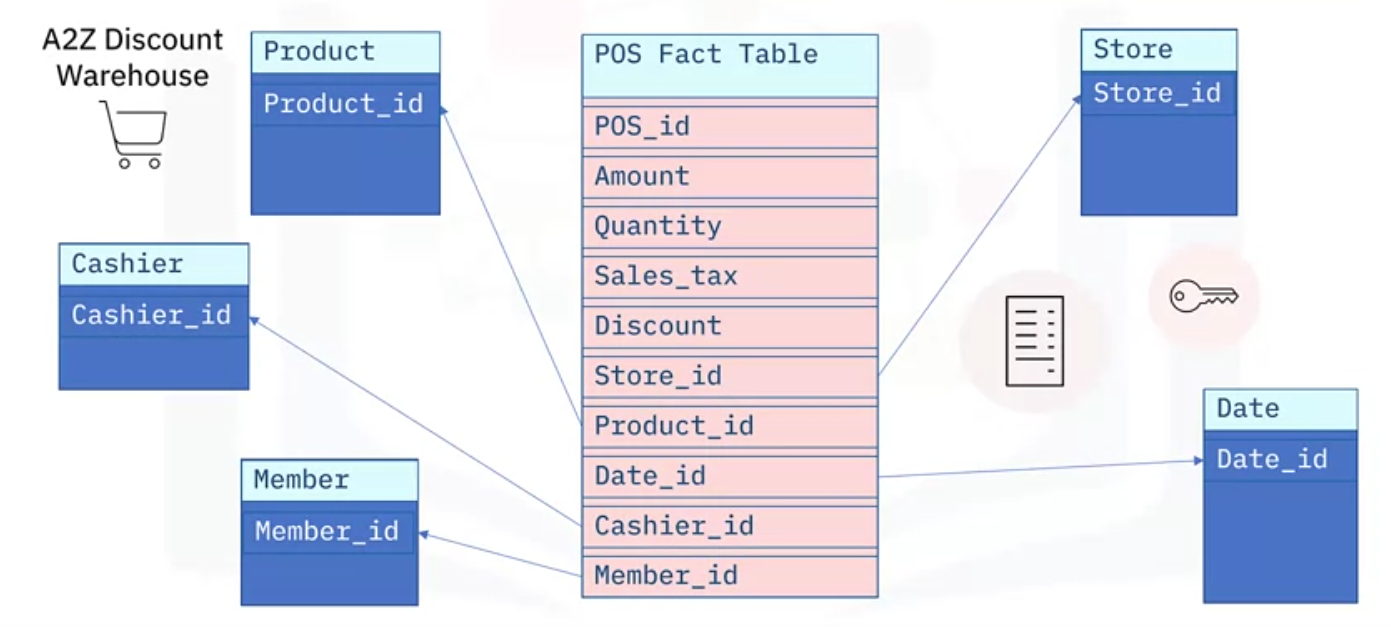
Now you are ready to start building your star schema for “A to Z Discount Warehouse.”
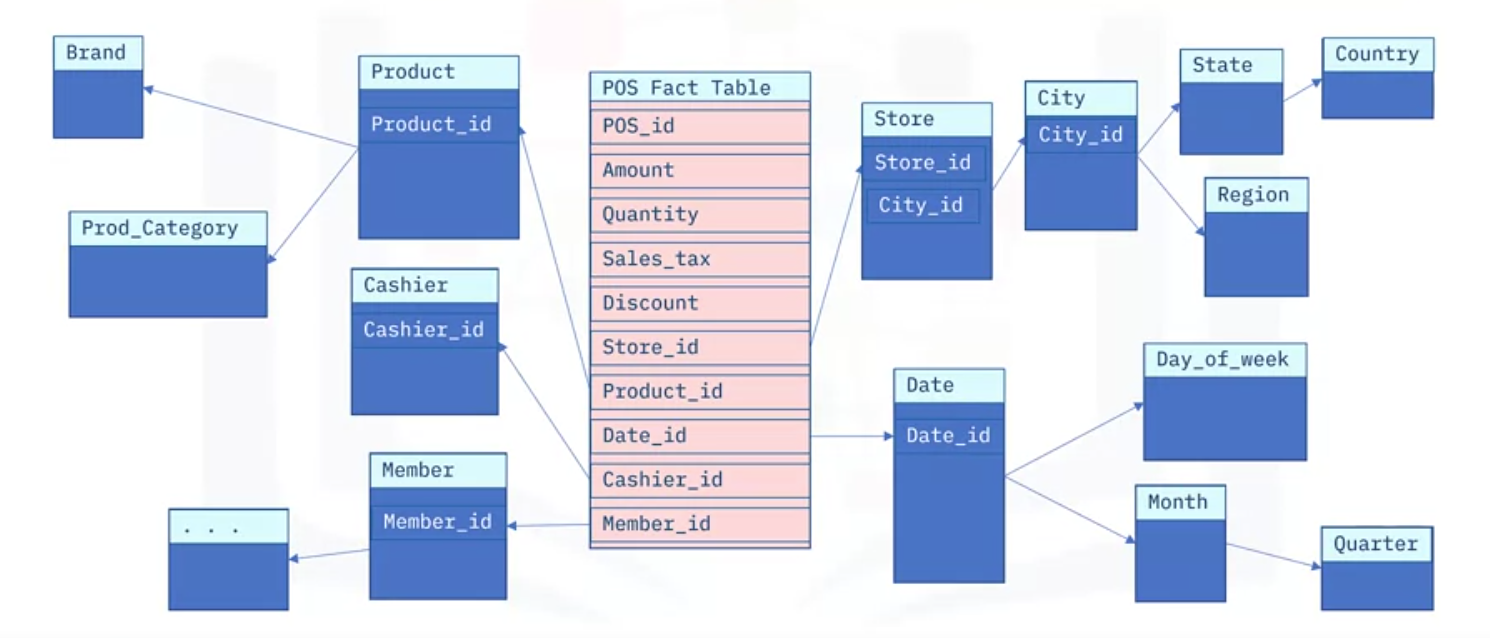
- At the center of your star schema sits a “point-of-sales fact table,” which contains a unique ID, called “P O S ID,” for each line item in the transaction,
- plus the following facts, or measures: the amount of the transaction in dollars, the quantity, or number of items involved, the sales tax, and any discount applied.
- There may be other facts to include, but these can be added later as you discover them.
- Each line item from a sales transaction has many dimensions associated with it. You include them as foreign keys in your fact table, or as links to the primary keys of your dimension tables.
- For example, the name of the store at which the item was sold is kept in a dimension table called “store,” which is identified in the fact-table by the value of the foreign “Store ID” key, which is the primary key for the Store table.
Dimension Tables
- Product information is stored in the Product table, which is uniquely identified by the “ProductID” key.
- Similarly, the date of the transaction is keyed by the “Date ID,” which cashier entered the transaction is keyed by the “Cashier ID,” and which member was involved is indicated by the “Member ID.”
This illustrates what a star schema might look like. Now let’s see what a snowflake schema will look like:
Snowflake Schema
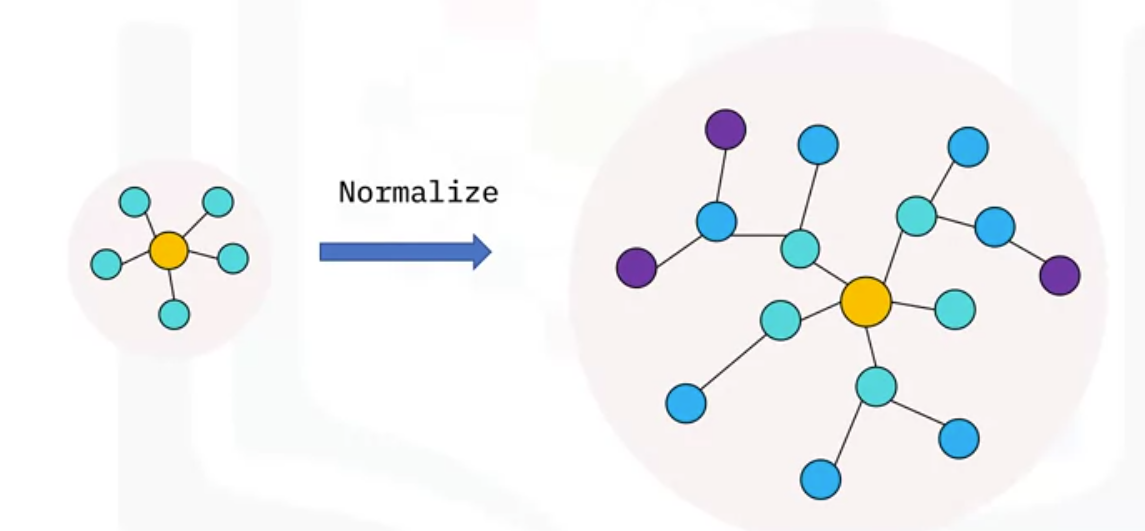
Let’s see how you can use normalization to extend your star schema to a snowflake schema. Starting with your star schema, you can extract some of the details of the dimension tables into their own separate dimension tables, creating a hierarchy of tables.
- A separate city table can be used to record which city the store is in, while a foreign ‘city id’ key would be included in the ‘Store’ table to maintain the link.
- You might also have tables and keys for the city’s state or province,
- and a pre-defined sales region for the store, and for which country the store resides in.
- We’ve left out the associated keys for simplicity.
- We can continue to normalize other dimensions, like the product’s brand, and a “product category” that it belongs to,
- the day of week and the month corresponding to the date, plus the quarter, and so on.
This normalized version of the star schema is called a snowflake schema, due to its multiple layers of branching which resembles a snowflake pattern. Much like how pointers are used to point to memory locations in computing, normalization reduces the memory footprint of the data.
Comparison
So why use schemas and how they differ?
Star schemas are optimized for reads and are widely used for designing data marts, whereas snowflake schemas are optimized for writes and are widely used for transactional data warehousing. A star schema is a special case of a snowflake schema in which all hierarchical dimensions have been denormalized, or flattened.
| Attribute | Star schema | Snowflake schema |
|---|---|---|
| Read speed | Fast | Moderate |
| Write speed | Moderate | Fast |
| Storage space | Moderate to high | Low to moderate |
| Data integrity risk | Low to moderate | Low |
| Query complexity | Simple to moderate | Moderate to complex |
| Schema complexity | Simple to moderate | Moderate to complex |
| Dimension hierarchies | Denormalized single tables | Normalized over multiple tables |
| Joins per dimension hierarchy | One | One per level |
| Ideal use | OLAP systems, Data Marts | OLTP systems |
Normalization
Both star and snowflake schemas benefit from the application of normalization. “Normalization reduces redundancy” is an idiom that points to a key advantage leveraged by both schemas. Normalizing a table means to create, for each dimension:
- A surrogate key to replace the natural key, that is, the unique values of the given column, and
- A lookup table to store the surrogate and natural key pairs.
Each surrogate key’s values are repeated exactly as many times within the normalized table as the natural key was before moving the natural key to its new lookup table. Thus, you did nothing to reduce the redundancy of the original table.
However, dimensions typically contain groups of items that appear frequently, such as a “city name” or “product category”. Since you only need one instance from each group to build your lookup table, your lookup table will have many fewer rows than your fact table. If there are child dimensions involved, then the lookup table may still have some redundancy in the child dimension columns. In other words, if you have a hierarchical dimension, such as “Country”, “State”, and “City”, you can repeat the process on each level to further reduce the redundancy. Notice that further normalizing your hierarchical dimensions has no effect on the size or content of your fact table - star and snowflake schema data models share identical fact tables.
Normalization reduces data size
When you normalize a table, you typically reduce its data size, because in the process you likely replace expensive data types, such as strings, with much smaller integer types. But to preserve the information content, you also need to create a new lookup table that contains the original objects. The question is, does this new table use less storage than the savings you just gained in the normalized table?
- For small data, this question is probably not worth considering, but for big data, or just data that is growing rapidly, the answer is yes, it is inevitable.
- Indeed, your fact table will grow much more quickly than your dimension tables, so normalizing your fact table, at least to the minimum degree of a star schema is likely warranted.
- Now the question is about which is better – star or snowflake?
Snowflake vs. Star DWs
- The snowflake, being completely normalized, offers the least redundancy and the smallest storage footprint. If the data ever changes, this minimal redundancy means the snowflaked data needs to be changed in fewer places than would be required for a star schema.
- In other words, writes are faster, and changes are easier to implement.
- However, due to the additional joins required in querying the data, the snowflake design can have an adverse impact on read speeds.
- By denormalizing to a star schema, you can boost your query efficiency.
- You can also choose a middle path in designing your data warehouse. You could opt for a partially normalized schema.
- You could deploy a snowflake schema as your basis and create views or even materialized views of denormalized data.
- You could for example simulate a star schema on top of a snowflake schema. At the cost of some additional complexity, you can select from the best of both worlds to craft an optimal solution to meet your requirements.
Practical differences
Most queries you apply to the dataset, regardless of your schema choice, go through the fact table. Your fact table serves as a portal to your dimension tables. The main practical difference between star and snowflake schema from the perspective of an analyst has to do with querying the data.
- You need more joins for a snowflake schema to gain access to the deeper levels of the hierarchical dimensions, which can reduce query performance over a star schema.
- Thus, data analysts and data scientists tend to prefer the simpler star schema.
- Snowflake schemas are generally good for designing data warehouses and in particular, transaction processing systems, while
- star schemas are better for serving data marts, or data warehouses that have simple fact-dimension relationships.
- For example, suppose you have point-of-sale records accumulating in an Online Transaction Processing System (OLTP) which are copied as a daily batch ETL process to one or more Online Analytics Processing (OLAP) systems where subsequent analysis of large volumes of historical data is carried out.
- The OLTP source might use a snowflake schema to optimize performance for frequent writes, while the OLAP system uses a star schema to optimize for frequent reads.
- The ETL pipeline that moves the data between systems includes a denormalization step which collapses each hierarchy of dimension tables into a unified parent dimension table.
Too much of a good thing?
There is always a tradeoff between storage and compute that should factor into your data warehouse design choices.
- For example, do your end-users or applications need to have precomputed, stored dimensions such as ‘day of week’, ‘month of year’, or ‘quarter’ of the year?
- Columns or tables which are rarely required are occupying otherwise usable disk space.
- It might be better to compute such dimensions within your SQL statements only when they are needed.
- For example, given a star schema with a date dimension table, you could apply the SQL ‘MONTH’ function as MONTH(dim_date.date_column) on demand instead of joining the precomputed month column from the MONTH table in a snowflake schema.
Scenario
Suppose you are handed a small sample of data from a very large dataset in the form of a table by your client who would like you to take a look at the data and consider potential schemas for a data warehouse based on the sample.
- Putting aside gathering specific requirements for the moment, you start by exploring the table and find that there are exactly two types of columns in the dataset - facts and dimensions.
- There are no foreign keys although there is an index. You think of this table as being a completely denormalized, or flattened dataset.
- You also notice that amongst the dimensions are columns with relatively expensive data types in terms of storage size, such as strings for names of people and places.
- At this stage you already know you could equally well apply either a star or snowflake schema to the dataset, thereby normalizing to the degree you wish.
- Whether you choose star or snowflake, the total data size of the central fact table will be dramatically reduced. This is because instead of using dimensions directly in the main fact table, you use surrogate keys, which are typically integers; and you move the natural dimensions to their own tables or hierarchy of tables which are referenced by the surrogate keys.
- Even a 32-bit integer is small compared to say a 10-character string (8 X 10 = 80 bits). Now it’s a matter of gathering requirements and finding some optimal normalization scheme for your schema.