Reminder what the Process stage means as defined in the Data Analysis Roadmap page:
Process
Guiding questions
- What tools are you choosing and why?
- Have you ensured your data’s integrity?
- What steps have you taken to ensure that your data is clean?
- How can you verify that your data is clean and ready to analyze?
- Have you documented your cleaning process so you can review and share those results?
Key tasks
Now that you know your data is credible and relevant to your problem, you’ll need to clean it so that your analysis will be error-free.
- Check the data for errors
- Transform the data into the right type
- Document the cleaning process
- Choose your tools
Data integrity
Data integrity involves the accuracy, completeness, consistency, and trustworthiness of data throughout its lifecycle.
A strong analysis depends on the integrity of the data, and data integrity usually depends on using a common format. Here are some other things to watch out for:
Data replication
Data replication compromising data integrity: One analyst copies a large dataset to check the dates. But because of memory issues, only part of the dataset is actually copied. The analyst would be verifying and standardizing incomplete data. That partial dataset would be certified as compliant but the full dataset would still contain dates that weren’t verified. Two versions of a dataset can introduce inconsistent results. A final audit of results would be essential to reveal what happened and correct all dates.
Data replication is the process of storing data in multiple locations. If you’re replicating data at different times in different places, there’s a chance your data will be out of sync. This data lacks integrity because different people might not be using the same data for their findings, which can cause inconsistencies.
Data transfer
Data transfer compromising data integrity: Another analyst checks the dates in a spreadsheet and chooses to import the validated and standardized data back to the database. But suppose the date field from the spreadsheet was incorrectly classified as a text field during the data import (transfer) process. Now some of the dates in the database are stored as text strings. At this point, the data needs to be cleaned to restore its integrity.
The process of copying data from a storage device to memory, or from one computer to another. If your data transfer is interrupted, you might end up with an incomplete data set, which might not be useful for your needs.
Data manipulation
Data manipulation compromising data integrity: When checking dates, another analyst notices what appears to be a duplicate record in the database and removes it. But it turns out that the analyst removed a unique record for a company’s subsidiary and not a duplicate record for the company. Your dataset is now missing data and the data must be restored for completeness.
Human error
Finally, data can also be compromised through human error, viruses, malware, hacking, and system failures, which can all lead to even more headaches.
Data contraints
As you progress in your data journey, you’ll come across many types of data constraints (or criteria that determine validity). The table below offers definitions and examples of data constraint terms you might come across.
| Data constraint | Definition | Examples |
|---|---|---|
| Data type | Values must be of a certain type: date, number, percentage, Boolean, etc. | If the data type is a date, a single number like 30 would fail the constraint and be invalid |
| Data range | Values must fall between predefined maximum and minimum values | If the data range is 10-20, a value of 30 would fail the constraint and be invalid |
| Mandatory | Values can’t be left blank or empty | If age is mandatory, that value must be filled in |
| Unique | Values can’t have a duplicate | Two people can’t have the same mobile phone number within the same service area |
| Regular expression (regex) patterns | Values must match a prescribed pattern | A phone number must match ###-###-#### (no other characters allowed) |
| Cross-field validation | Certain conditions for multiple fields must be satisfied | Values are percentages and values from multiple fields must add up to 100% |
| Primary-key | (Databases only) value must be unique per column | A database table can’t have two rows with the same primary key value. A primary key is an identifier in a database that references a column in which each value is unique. More information about primary and foreign keys is provided later in the program. |
| Set-membership | (Databases only) values for a column must come from a set of discrete values | Value for a column must be set to Yes, No, or Not Applicable |
| Foreign-key | (Databases only) values for a column must be unique values coming from a column in another table | In a U.S. taxpayer database, the State column must be a valid state or territory with the set of acceptable values defined in a separate States table |
| Accuracy | The degree to which the data conforms to the actual entity being measured or described | If values for zip codes are validated by street location, the accuracy of the data goes up. |
| Completeness | The degree to which the data contains all desired components or measures | If data for personal profiles required hair and eye color, and both are collected, the data is complete. |
| Consistency | The degree to which the data is repeatable from different points of entry or collection | If a customer has the same address in the sales and repair databases, the data is consistent. |
Insufficient data
When you are getting ready for data analysis, you might realize you don’t have the data you need or you don’t have enough of it. In some cases, you can use what is known as proxy data in place of the real data. Think of it like substituting oil for butter in a recipe when you don’t have butter. In other cases, there is no reasonable substitute and your only option is to collect more data.
Data can be insufficient for a number of reasons. Insufficient data has one or more of the following problems:
Comes from only one source
Continuously updates and is incomplete
Is outdated
Is geographically limited
No data
| Possible Solutions | Examples of solutions in real life |
|---|---|
| Gather the data on a small scale to perform a preliminary analysis and then request additional time to complete the analysis after you have collected more data. | If you are surveying employees about what they think about a new performance and bonus plan, use a sample for a preliminary analysis. Then, ask for another 3 weeks to collect the data from all employees. |
| If there isn’t time to collect data, perform the analysis using proxy data from other datasets. This is the most common workaround. | If you are analyzing peak travel times for commuters but don’t have the data for a particular city, use the data from another city with a similar size and demographic. |
Too little data
| Possible Solutions | Examples of solutions in real life |
|---|---|
| Do the analysis using proxy data along with actual data. | If you are analyzing trends for owners of golden retrievers, make your dataset larger by including the data from owners of labradors. |
| Adjust your analysis to align with the data you already have. | If you are missing data for 18- to 24-year-olds, do the analysis but note the following limitation in your report: this conclusion applies to adults 25 years and older only. |
Wrong data
including data with errors*
| Possible Solutions | Examples of solutions in real life |
|---|---|
| If you have the wrong data because requirements were misunderstood, communicate the requirements again. | If you need the data for female voters and received the data for male voters, restate your needs. |
| Identify errors in the data and, if possible, correct them at the source by looking for a pattern in the errors. | If your data is in a spreadsheet and there is a conditional statement or boolean causing calculations to be wrong, change the conditional statement instead of just fixing the calculated values. |
| If you can’t correct data errors yourself, you can ignore the wrong data and go ahead with the analysis if your sample size is still large enough and ignoring the data won’t cause systematic bias. | If your dataset was translated from a different language and some of the translations don’t make sense, ignore the data with bad translation and go ahead with the analysis of the other data. |
* Important note: Sometimes data with errors can be a warning sign that the data isn’t reliable. Use your best judgment.
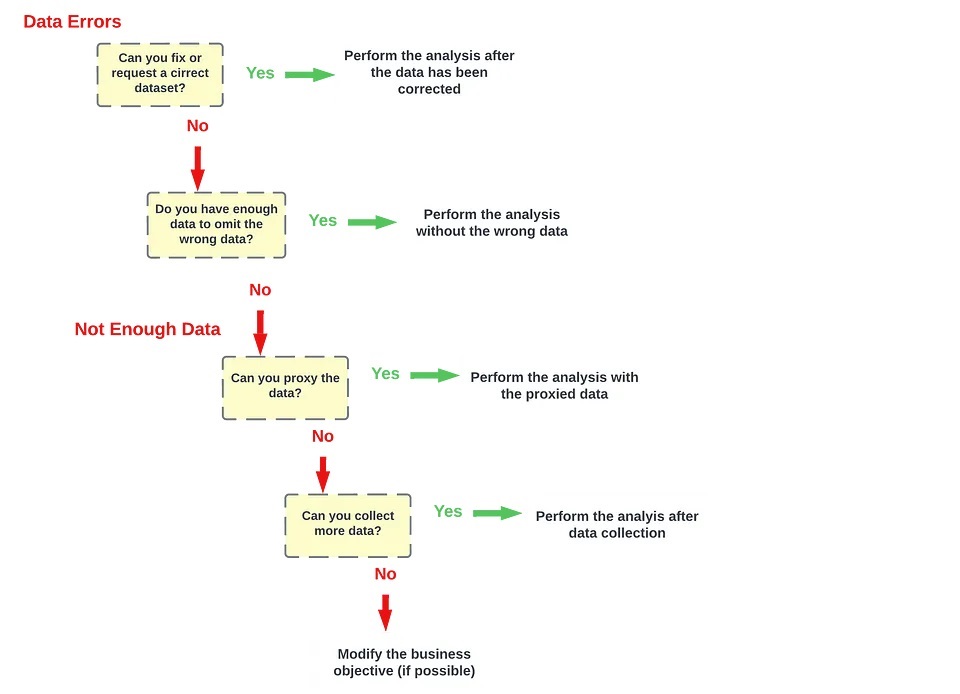
Decision Tree
Use the following decision tree as a reminder of how to deal with data errors or not enough data:
Sample size
We covered sample size in experimental design. Before you dig deeper into sample size, familiarize yourself with these terms and definitions:
| Terminology | Definitions |
|---|---|
| Population | The entire group that you are interested in for your study. For example, if you are surveying people in your company, the population would be all the employees in your company. |
| Sample | A subset of your population. Just like a food sample, it is called a sample because it is only a taste. So if your company is too large to survey every individual, you can survey a representative sample of your population. |
| Margin of error | Since a sample is used to represent a population, the sample’s results are expected to differ from what the result would have been if you had surveyed the entire population. This difference is called the margin of error. The smaller the margin of error, the closer the results of the sample are to what the result would have been if you had surveyed the entire population. |
| Confidence level | How confident you are in the survey results. For example, a 95% confidence level means that if you were to run the same survey 100 times, you would get similar results 95 of those 100 times. Confidence level is targeted before you start your study because it will affect how big your margin of error is at the end of your study. |
| Confidence interval | The range of possible values that the population’s result would be at the confidence level of the study. This range is the sample result +/- the margin of error. |
| Statistical significance | The determination of whether your result could be due to random chance or not. The greater the significance, the less due to chance. |
Things to remember
When figuring out a sample size, here are things to keep in mind:
Don’t use a sample size less than 30. It has been statistically proven that 30 is the smallest sample size where an average result of a sample starts to represent the average result of a population.
The confidence level most commonly used is 95%, but 90% can work in some cases.
Increase the sample size to meet specific needs of your project:
For a higher confidence level, use a larger sample size
To decrease the margin of error, use a larger sample size
For greater statistical significance, use a larger sample size
Note: Sample size calculators use statistical formulas to determine a sample size. More about these are coming up in the course! Stay tuned.
Why a minimum of 30?
This recommendation is based on the Central Limit Theorem (CLT) in the field of probability and statistics. As sample size increases, the results more closely resemble the normal (bell-shaped) distribution from a large number of samples. A sample of 30 is the smallest sample size for which the CLT is still valid. Researchers who rely on regression analysis – statistical methods to determine the relationships between controlled and dependent variables – also prefer a minimum sample of 30.
Proxy Data
Sometimes the data to support a business objective isn’t readily available. This is when proxy data is useful. Take a look at the following scenarios and where proxy data comes in for each example:
| Business scenario | How proxy data can be used |
|---|---|
| A new car model was just launched a few days ago and the auto dealership can’t wait until the end of the month for sales data to come in. They want sales projections now. | The analyst proxies the number of clicks to the car specifications on the dealership’s website as an estimate of potential sales at the dealership. |
| A brand new plant-based meat product was only recently stocked in grocery stores and the supplier needs to estimate the demand over the next four years. | The analyst proxies the sales data for a turkey substitute made out of tofu that has been on the market for several years. |
| The Chamber of Commerce wants to know how a tourism campaign is going to impact travel to their city, but the results from the campaign aren’t publicly available yet. | The analyst proxies the historical data for airline bookings to the city one to three months after a similar campaign was run six months earlier. |
Open (public) datasets
If you are part of a large organization, you might have access to lots of sources of data. But if you are looking for something specific or a little outside your line of business, you can also make use of open or public datasets. (You can refer to this Medium article for a brief explanation of the difference between open and public data.)
Here’s an example. A nasal version of a vaccine was recently made available. A clinic wants to know what to expect for contraindications, but just started collecting first-party data from its patients. A contraindication is a condition that may cause a patient not to take a vaccine due to the harm it would cause them if taken. To estimate the number of possible contraindications, a data analyst proxies an open dataset from a trial of the injection version of the vaccine. The analyst selects a subset of the data with patient profiles most closely matching the makeup of the patients at the clinic.
There are plenty of ways to share and collaborate on data within a community. Kaggle (kaggle.com) which we previously introduced, has datasets in a variety of formats including the most basic type, Comma Separated Values (CSV) files.
CSV, JSON, SQLite, and BigQuery datasets
CSV: Check out this Credit card customers dataset, which has information from 10,000 customers including age, salary, marital status, credit card limit, credit card category, etc. (CC0: Public Domain, Sakshi Goyal).
JSON: Check out this JSON dataset for trending YouTube videos (CC0: Public Domain, Mitchell J).
SQLite: Check out this SQLite dataset for 24 years worth of U.S. wildfire data (CC0: Public Domain, Rachael Tatman).
BigQuery: Check out this Google Analytics 360 sample dataset from the Google Merchandise Store (CC0 Public Domain, Google BigQuery).
Refer to the Kaggle documentation for datasets for more information and search for and explore datasets on your own at kaggle.com/datasets.
As with all other kinds of datasets, be on the lookout for duplicate data and ‘Null’ in open datasets. Null most often means that a data field was unassigned (left empty), but sometimes Null can be interpreted as the value, 0. It is important to understand how Null was used before you start analyzing a dataset with Null data.
Test your data
Statistically Significant
“Statistically significant” is a term that is used in statistics. In basic terms, if a test is statistically significant, it means the results of the test are real and not an error caused by random chance. .8 r 80% is the minimum you should accept as value
Sample size
A sample size calculator in Google Sheets tells you how many people you need to interview (or things you need to test) to get results that represent the target population. Let’s review some terms you will come across when using a sample size calculator:
Confidence level
The probability that your sample size accurately reflects the greater population. 99% is ideal specially in pharmaceuticals. 90-95% is ok for others.
Margin of error
The maximum amount that the sample results are expected to differ from those of the actual population.
Population
This is the total number you hope to pull your sample from.
Sample
A part of a population that is representative of the population.
Estimated response rate
If you are running a survey of individuals, this is the percentage of people you expect will complete your survey out of those who received the survey.
Sample size calculator
In order to use a sample size calculator, you need to have the population size, confidence level, and the acceptable margin of error already decided so you can input them into the tool. If this information is ready to go, check out these sample size calculators below:
What to do with the results
After you have plugged your information into one of these calculators, it will give you a recommended sample size. Keep in mind, the calculated sample size is the minimum number to achieve what you input for confidence level and margin of error. If you are working with a survey, you will also need to think about the estimated response rate to figure out how many surveys you will need to send out. For example, if you need a sample size of 100 individuals and your estimated response rate is 10%, you will need to send your survey to 1,000 individuals to get the 100 responses you need for your analysis.
Margin of error
Margin of error (calculator in Google Sheets) is the maximum amount that the sample results are expected to differ from those of the actual population. More technically, the margin of error defines a range of values below and above the average result for the sample. The average result for the entire population is expected to be within that range.
In baseball
Imagine you are playing baseball and that you are up at bat. The crowd is roaring, and you are getting ready to try to hit the ball. The pitcher delivers a fastball traveling about 90-95mph, which takes about 400 milliseconds (ms) to reach the catcher’s glove. You swing and miss the first pitch because your timing was a little off. You wonder if you should have swung slightly earlier or slightly later to hit a home run. That time difference can be considered the margin of error, and it tells us how close or far your timing was from the average home run swing.
In marketing
The margin of error is also important in marketing. Let’s use A/B testing as an example. A/B testing (or split testing) tests two variations of the same web page to determine which page is more successful in attracting user traffic and generating revenue. User traffic that gets monetized is known as the conversion rate. A/B testing allows marketers to test emails, ads, and landing pages to find the data behind what is working and what isn’t working. Marketers use the confidence interval (determined by the conversion rate and the margin of error) to understand the results.
For example, suppose you are conducting an A/B test to compare the effectiveness of two different email subject lines to entice people to open the email. You find that subject line A: “Special offer just for you” resulted in a 5% open rate compared to subject line B: “Don’t miss this opportunity” at 3%.
Does that mean subject line A is better than subject line B? It depends on your margin of error. If the margin of error was 2%, then subject line A’s actual open rate or confidence interval is somewhere between 3% and 7%. Since the lower end of the interval overlaps with subject line B’s results at 3%, you can’t conclude that there is a statistically significant difference between subject line A and B. Examining the margin of error is important when making conclusions based on your test results.
Calculate margin of error
All you need is population size, confidence level, and sample size. In order to better understand this calculator, review these terms:
Confidence level: A percentage indicating how likely your sample accurately reflects the greater population
Population: The total number you pull your sample from
Sample: A part of a population that is representative of the population
Margin of error: The maximum amount that the sample results are expected to differ from those of the actual population
In most cases, a 90% or 95% confidence level is used. But, depending on your industry, you might want to set a stricter confidence level. A 99% confidence level is reasonable in some industries, such as the pharmaceutical industry.
After you have settled on your population size, sample size, and confidence level, plug the information into a margin of error calculator like the ones below:
Dirty data
Dirty data is data that is incomplete, incorrect, or irrelevant to the problem you are trying to solve.
Types
Duplicate data
| Description | Possible causes | Potential harm to businesses |
|---|---|---|
| Any data record that shows up more than once | Manual data entry, batch data imports, or data migration | Skewed metrics or analyses, inflated or inaccurate counts or predictions, or confusion during data retrieval |
Outdated data
| Description | Possible causes | Potential harm to businesses |
|---|---|---|
| Any data that is old which should be replaced with newer and more accurate information | People changing roles or companies, or software and systems becoming obsolete | Inaccurate insights, decision-making, and analytics |
Incomplete data
| Description | Possible causes | Potential harm to businesses |
|---|---|---|
| Any data that is missing important fields | Improper data collection or incorrect data entry | Decreased productivity, inaccurate insights, or inability to complete essential services |
Incorrect/inaccurate data
| Description | Possible causes | Potential harm to businesses |
|---|---|---|
| Any data that is complete but inaccurate | Human error inserted during data input, fake information, or mock data | Inaccurate insights or decision-making based on bad information resulting in revenue loss |
Inconsistent data
| Description | Possible causes | Potential harm to businesses |
|---|---|---|
| Any data that uses different formats to represent the same thing | Data stored incorrectly or errors inserted during data transfer | Contradictory data points leading to confusion or inability to classify or segment customers |
Mistakes to Avoid
Not checking for spelling errors
Misspellings can be as simple as typing or input errors. Most of the time the wrong spelling or common grammatical errors can be detected, but it gets harder with things like names or addresses. For example, if you are working with a spreadsheet table of customer data, you might come across a customer named “John” whose name has been input incorrectly as “Jon” in some places. The spreadsheet’s spellcheck probably won’t flag this, so if you don’t double-check for spelling errors and catch this, your analysis will have mistakes in it.
Forgetting to document errors
Documenting your errors can be a big time saver, as it helps you avoid those errors in the future by showing you how you resolved them. For example, you might find an error in a formula in your spreadsheet. You discover that some of the dates in one of your columns haven’t been formatted correctly. If you make a note of this fix, you can reference it the next time your formula is broken, and get a head start on troubleshooting. Documenting your errors also helps you keep track of changes in your work, so that you can backtrack if a fix didn’t work.
Not checking for misfielded values
A misfielded value happens when the values are entered into the wrong field. These values might still be formatted correctly, which makes them harder to catch if you aren’t careful. For example, you might have a dataset with columns for cities and countries. These are the same type of data, so they are easy to mix up. But if you were trying to find all of the instances of Spain in the country column, and Spain had mistakenly been entered into the city column, you would miss key data points. Making sure your data has been entered correctly is key to accurate, complete analysis.
Overlooking missing values
Missing values in your dataset can create errors and give you inaccurate conclusions. For example, if you were trying to get the total number of sales from the last three months, but a week of transactions were missing, your calculations would be inaccurate. As a best practice, try to keep your data as clean as possible by maintaining completeness and consistency.
Only looking at a subset of the data
It is important to think about all of the relevant data when you are cleaning. This helps make sure you understand the whole story the data is telling, and that you are paying attention to all possible errors. For example, if you are working with data about bird migration patterns from different sources, but you only clean one source, you might not realize that some of the data is being repeated. This will cause problems in your analysis later on. If you want to avoid common errors like duplicates, each field of your data requires equal attention.
Losing track of business objectives
When you are cleaning data, you might make new and interesting discoveries about your dataset– but you don’t want those discoveries to distract you from the task at hand. For example, if you were working with weather data to find the average number of rainy days in your city, you might notice some interesting patterns about snowfall, too. That is really interesting, but it isn’t related to the question you are trying to answer right now. Being curious is great! But try not to let it distract you from the task at hand.
Not fixing the source of the error
Fixing the error itself is important. But if that error is actually part of a bigger problem, you need to find the source of the issue. Otherwise, you will have to keep fixing that same error over and over again. For example, imagine you have a team spreadsheet that tracks everyone’s progress. The table keeps breaking because different people are entering different values. You can keep fixing all of these problems one by one, or you can set up your table to streamline data entry so everyone is on the same page. Addressing the source of the errors in your data will save you a lot of time in the long run.
Not analyzing the system prior to data cleaning
If we want to clean our data and avoid future errors, we need to understand the root cause of your dirty data. Imagine you are an auto mechanic. You would find the cause of the problem before you started fixing the car, right? The same goes for data. First, you figure out where the errors come from. Maybe it is from a data entry error, not setting up a spell check, lack of formats, or from duplicates. Then, once you understand where bad data comes from, you can control it and keep your data clean.
Not backing up your data prior to data cleaning
It is always good to be proactive and create your data backup before you start your data clean-up. If your program crashes, or if your changes cause a problem in your dataset, you can always go back to the saved version and restore it. The simple procedure of backing up your data can save you hours of work– and most importantly, a headache.
Not accounting for data cleaning in your deadlines/process
All good things take time, and that includes data cleaning. It is important to keep that in mind when going through your process and looking at your deadlines. When you set aside time for data cleaning, it helps you get a more accurate estimate for ETAs for stakeholders, and can help you know when to request an adjusted ETA.
Data mapping
Data mapping is the process of matching fields from one database to another. This is very important to the success of data migration, data integration, and lots of other data management activities.
The first step to data mapping is identifying what data needs to be moved. This includes the tables and the fields within them. We also need to define the desired format for the data once it reaches its destination. There are lots of mapping software out there, just remember to check they are compatible to Excel, SQL, Tableau and others
Schema
a schema is a way of describing how something is organized.
Clean with SQL
SQL is the primary way data analysts extract data from databases. As a data analyst, you will work with databases all the time, which is why SQL is such a key skill. If it is stored in a database, then SQL is the best tool for the job. But if it is stored in a spreadsheet, then you’ll have to perform your analysis in that spreadsheet. In that scenario, you could create a pivot table of the data and then apply specific formulas and filters to the data.
Spreadsheets and SQL both have their advantages and disadvantages:
| Features of Spreadsheets | Features of SQL Databases |
|---|---|
| Smaller data sets | Larger datasets |
| Enter data manually | Access tables across a database |
| Create graphs and visualizations in the same program | Prepare data for further analysis in another software |
| Built-in spell check and other useful functions | Fast and powerful functionality |
| Best when working solo on a project | Great for collaborative work and tracking queries run by all users |
Verification
Verification is a process to
- confirm that a data-cleaning effort was well-executed and
- the resulting data is accurate and reliable
- manually cleaning data to compare your expectations with what’s actually present.
When verifying
- Consider the business problem
- Consider the goal
- Consider the data